| |
منهجية جديدة لبناء طريقة لتجزئة البيانات المكانية الكبيرة:
3.1 تحديد الأهداف
من خلال دراسة الأعمال ذات الصلة يمكن وضع الأهداف الرئيسية التالية لتجزئة البيانات المكانية الكبيرة:
- تجزئة مجموعة البيانات إلى عدة كتل من البيانات يمكن معالجتها بشكل تفرعي.
- الاستفادة من الواصفات المكانية لكائنات مجموعة البيانات في تنفيذ عملية التجزئة.
- تخزين البيانات المتجاورة جغرافياً في أجزاء متقاربة تخزينياً بغرض التقليل من استخدام الشبكة في تبادل البيانات.
- تحقيق توازن في حجم الكتل بحيث تكون متقاربة في الحجم تفادياً لزيادة العبء في عُقد حاسوبية معينة على حساب العُقد الأخرى.
- تنفيذ الاستعلامات المكانية على البيانات بسرعة أكبر مع الحفاظ على دقة نتائج لاستعلام.
- زيادة كفاءة استخدام الموارد الحاسوبية وفعالية الخوارزميات المكانية في الوصول إلى الأهداف المطلوبة من قبل التطبيق.
3.2 توصيف عام لعملية التجزئة المكانية
عملية التجزئة المكانية هي عملية يتم تنفيذها على مجموعة بيانات. يمتلك كل كائن من مجموعة البيانات واصفات مكانية متعلقة بالموقع الجغرافي والشكل الهندسي، وأخرى وصفية (قياسات وملاحظات متعلقة بالكائن). ينتج عن تنفيذ عملية التجزئة عدة مجموعات بيانات جزئية يحتوي كل منها مجموعة من الكائنات الموجودة في المجموعة الأساسية.
إن الحصول على أجزاء متوازنة يقتضي ان يكون عدد الكائنات أو عب المعالجة للكائنات موزعاً بشكل متوازن على مجموعات البيانات الجزئية. تعمل عملية التجزئة على توليد معرف خاص بكل كائن لتحديد الجزء أو مجموعة البيانات الجزئية التي سيتم ضم الكائن إليها وهذا يمكن تسميته بمخطط التجزئة Partitioning Scheme.
إن الشكل الهندسي ودرجة تعقيده والكفاءة في استخدام الفراغ الجغرافي يلعب دوراً في التجزئة المكانية، وبالتالي لا يمكن اعتبار عمليات التجزئة التي تستخدم طرق لا تعتمد على الفهرسة المكانية أو لا تأخذ بعين الاعتبار الواصفات المكانية من إحداثية وشكل هندسي أو الواصفات النصية المعبرة عن المكان من ضمن خوارزميات التجزئة المكانية بل هي خوارزميات للتجزئة التقليدية للبيانات.
تهدف عملية التجزئة المكانية إلى جعل الاستعلامات المكانية أكثر سرعة أي ان الوظائف الجغرافية مثل الاحتواء والتجاور والتداخل والتراكب يتم تنفيذها على مجموعة البيانات المجزأة بشكل أسرع من تنفيذها على مجموعة البيانات الأصلية مع شرط لازم وغير كافي هو الحفاظ على دقة وصحة النتائج. إن سرعة الاستعلام ودقة النتائج محددات أساسية لتقييم فعالية طريقة التجزئة. اما كفاءة عملية التجزئة فهي مرتبطة بحجم الموارد الحاسوبية المستهلكة في تنفيذ العملية مثل دورات المعالج وحجم الذاكرة وحجم التخزين على القرص وحجم استخدام الحزمة الشبكية.
3.3 نموذج رياضي لعملية التجزئة المكانية
لدينا مجموعة بيانات DS تحتوي على مجموعة من الكائنات المكانية SO المتجانسة من حيث الشكل الهندسي.
عدد الكائنات في مجموعة البيانات n
أو n=|DS|
حجم التخزين لكل كائن SO هو s
نستخدم الرمز SO=DSi للتعبير عن الكائن ذو الترتيب i في مجموعة البيانات.
يأخذ SO الشكل العام التالي:
SO= {x,y,z,geometry,crs│att1,att2…}
حيث تمثل x,y,z,geometry,crs الواصفات المكانية للكائن وatti مجموعة الواصفات غير المكانية (الواصفات الغرضية) للكائن. تهدف عملية تجزئة البيانات إلى تقسيم مجموعة البيانات إلى عدد من الأجزاء k يتضمن كل جزء عدد من الكائنات SO نعبر عن كل جزء بالرمز SubDSi
وبحيث يتحقق الشرط:
∀i ∈[1,k]:SubDSi ⊆DS
ويكون حجم كل جزء
n=|SubDSi|
لبناء عملية التجزئة يجب أن يتم توليد مجموعة من المعرفات الفريدة عددها k نعبر عنها بالرمز PartID بحيث يتحقق الشرط:
∀SO ∈SubDSi:SO.PartID= PartIDi
في التجزئة المكانية يتم توليد PartID باستخدام تابع للمتحولات الممثلة للواصفات المكانية:
PartID= f(SO.x,SO.y,SO.z,SO.Geometry)
في التجزئة المكانية المتوازنة تكون المجموعات الجزئية SubDS متساوية تقريباً من حيث عدد العناصر أو الحجم. أي أنه من أجل أي مجموعتين جزئيتين p,q يتحقق أحد أو كلا الشرطين التاليين:
الشرط الأول
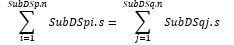
الشرط الثاني:
|SubDSp|= |SubDSq|
نعبر عن عدد المهام التي يستطيع النظام تنفيذها في نفس الوقت بالرمز P من الممكن أن تمثل P عدد العمليات البرمجية التفرعية Processes أو عدد المسارات المتاحة في نواة المعالجة Threads أو عدد نوى المعالج Cores أو عدد العقد الحاسوبية المتصلة شبكياً في العنقود Cluster Nodes.
f:DS→{SubDSi}:i[1..k]& k=P
تأخذ التجزئة المكانية الديناميكية بعين الاعتبار حجم استخدام أو معدل الوصول إلى كائنات البيانات وبالتالي يتم استخدام بنية معطيات خاصة لتخزين احصاءات عن عدد مرات ونسبة ظهور كل كائن من مجموعة البيانات في نتائج الاستعلامات خلال فترة زمنية محددة يمكن ان تكون فترة سابقة أو في الزمن الحقيقي. حيث يمكن إضافة معامل للتعبير عن حجم الوصول إلى كائن معين.
Ui=(Count(SOi)) / (Total Count)
يمكن استخدام الحمل الحالي Work Load لكل
عقدة معالجة في لحظة زمنية معينة لتعريف تابع تكلفة Cost Function استخدامه في التجزئة المكانية الدينايميكة للبيانات.
WL(t,i):f(CPU,Memory,DiskIO,Network)
3.4 نموذج برمجي لعمية التجزئة المكانية
المتطلب الوظيفي الأساسي لعملية التجزئة المكانية هو قراءة مجموعة بيانات مكانية كبيرة وتخزينها في بنية معطيات مناسبة ثم تنفيذ طريقة للتجزئة لإنتاج معرفات فريدة تسمح بتجزئة مجموعة البيانات إلى مجموعات جزئية. يمثل الشكل (1) نموذج لطريقة عامة لتجزئة البيانات المكانية حيث يمكن بناء على هذا النموذج تصميم صف برمجي Class لتحقيق عملية التجزئة المكانية وفق شبه الترميز التالي:
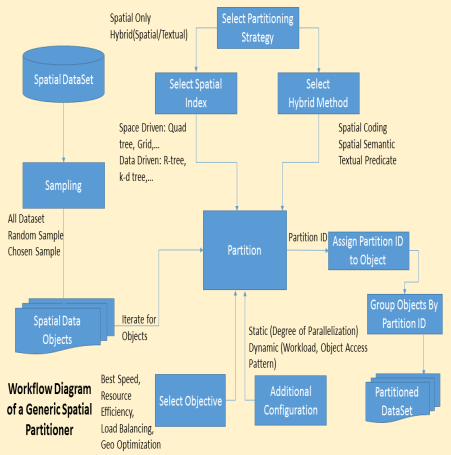
الشكل (1) – مخطط طريقة عامة لتجزئة البيانات المكانية
Class Partitioner {
partitioning_strategy={'Spatial', 'Textual', 'Hybrid'}
partitioning_type={'Static', 'Dynamic'}
spatial_index_algorithm={'Grid','R-tree','Q-tree'}
partitioining_objective={'Balanced', 'WorkLoad Aware', 'Fast', 'GeoEfficient', 'Resource Efficient'}
sampling_type={'All', 'Random', 'Selected'}
init_parameters={partitioning_strategy,partitioning_type,spatial_index_algorithm,partitioning_objective,sampling_type}
Constructor (init paramters)
{
}
PreparePartitioning (SpatialDataSet DS)
{
For each SO in DS
SO.partition_id=Partition(SO)
}
Partition(SpatialObject SO)
{
…….
Return(Partition_ID)
}
} |
يبين الشكل (2) نموذج عملي عن اعتماد النموذج البرمجي في بناء وظيفة للتجزئة المكانية ضمن بيئة Dask_Geopandas [20] للمعالجة التفرعية للبيانات المكانية الكبيرة بلغة Python كبديل لوظيفة التجزئة التقليدية المتوفرة مع البيئة للتحقق عن إمكانية استخدام النموذج في بناء تنفيذ عملية تجزئة مكانية ساكنة باستخدام فهرس مكانية لكامل مجموعة البيانات مع تحقيق الترابط بين عملية التجزئة ودرجة التفرعية المتاحة في النظام.

الشكل (2) – مثال عملي عن استخدام النموذج
3.5 تصميم بيئة الاختبار
يتطلب تقييم أداء طريقة التجزئة تنفيذ الاختبارات اللازمة للحصول على نتائج موثوقة تسمح باتخاذ القرار التصميمي الصحيح. يتطلب بناء بيئة الاختبار اختيار مجموعة البيانات Dataset ومواصفات النظام الحاسوبي والوظائف المستخدمة في الاختبار والقياسات الكمية والنوعية Metrics المطلوبة للتقييم.
يرتبط اختيار مجموعة البيانات المستخدمة في تنفيذ الاختبار بمجموعة من القرارات التصميمية نذكر منها:
- استخدام مجموعة بيانات حقيقية أو مجموعة بيانات مولدة حاسوبياً Synthetic.
- حجم مجموعة البيانات من حيث عدد السجلات أو من حيث حجم السجل الواحد وعادة ما يتم تنفيذ الاختبار على عدة مجموعات بيانات متجانسة من حيث البنية ومختلفة من حيث عدد السجلات.
- الشكل الهندسي للكائنات المخزنة في مجموعة البيانات (نقطة، مضلع)، ونموذج التوزيع الجغرافي والترابط المكاني الذاتي لكائنات مجموعة البيانات.
يجب أن يتمتع النظام الحاسوبي المستخدم في الاختبار بقابلية تنفيذ عدة عمليات على التوازي سواء كان ذلك على مستوى نوى المعالجات أو من خلال استخدام العنقود الحاسوبي. ويتضمن النظام الحاسوبي إلى جانب المكونات المادية، المكونات البرمجية التي تسمح بإدارة موارد النظام وجدولة وتوزيع المهام على المعالجات المتوفرة وإضافة وحذف العقد من العنقود. من الممكن أيضاً استخدام بيئة الحوسبة السحابية لتنفيذ الاختبارات المتعلقة بالبيانات المكانية.
أبرز العمليات المكانية المستخدمة في اختبار نظم معالجة البيانات المكانية هي استعلامات المجال الجغرافي Range Query واستعلامات الدمج المكاني Spatial Join واستعلامات إيجاد الجوار الأقرب Nearest Neighbor. أما بالنسبة لأكثر المقاييس الكمية والنوعية المستخدمة في تقييم الأداء فهي سرعة تنفيذ عملية التجزئة، وسرعة تنفيذ الاستعلام بعد تنفيذ التجزئة مقارنة بسرعة تنفيذه بدون التجزئة، وحجم استخدام الموارد من زمن المعالج والذاكرة وعمليات القراءة/الكتابة على الأقراص وحجم المرور الشبكي، والانحراف المعياري لتوزيع البيانات على الأجزاء ومن الممكن تطوير محددات نوعية جديدة تتضمن عدة قياسات كمية.
up
|
| |
Reference
1, Mohammad Mahmud, Joshua Huang, Salman Salloum et al,2020,A Survey of Data Partitioning and Sampling Methods to Support Big Data Analysis, Big Data Mining and Analytics, 3(2): 85-101.
2, Hadoop,https://hadoop.apache.org, last accessed 08/06/2022
3, Claudia Dolci, Dante Salvini, Michael Schrattner, Robert Weibel,2010, Spatial Partitioning and Indexing, Information Technology Training Alliance (GITTA) http://www.gitta.info 8.11.2010
4,AblimitAji,FushengWang,HoangVo , Rubao Lee, Qiaoling Liu,XiaodongZhang,JoelSaltz,2013, Hadoop GIS: A High Performance Spatial DataWarehousing System over MapReduce,Proceedings of the VLDB Endowment 21508097/13/09, Vol. 6, No. 2013
5, Ahmed Eldawy, Mohamed F. Mokbel, SpatialHadoop: A MapReduce Framework for Spatial Data
6, Apache Sedona,https://Sedona.apache.org, last accessed 08/06/2022
7,Jia Yu, Jinxuan Wu, Mohamed Sarwat, GeoSpark: A Cluster Computing Framework forProcessing Spatial Data, NationalGeospatial-Intelligence Agency (NGA) Foresight Project
8, Alberto Belussi , Sara Migliorini and Ahmed Eldawy,2020,Skewness-Based Partitioning in SpatialHadoop,ISPRS Int. J. Geo-Inf. 2020, 9, 201; doi:10.3390/ijgi9040201
9, Nikolaos Niopas,2019,Benchmarking data partitioning techniques in HDFS for big real spatial data, University of Amsterdam
10, Afsin Akdogan,2015, Partitioning, Indexing and Querying Spatial Data on Cloud, A PhD Dissertation , Faculty of the USC graduate school University of Southern California ,December 2015
11, Karen D. Devine, Erik G. Boman, George Karypis,2008, Partitioning and Load Balancing for Emerging Parallel Applications and Architectures, DOI: 10.1137/1.9780898718133.ch6
12, Ahmed Elashry, Abdulaziz Shehab, Alaa. M. Riad, Ahmed Aboul-fotouh, An Efficient Partitioning Technique in SpatialHadoop, IJICIS, Vol.18, No. 1
13, Xiaochuang Yao, Mohamed F. Mokbel, LouaiAlarabi, Ahmed Eldawy, Jianyu Yang,
Wenju Yun, Lin Li, Sijing Ye, Dehai Zhu,2017, Spatial coding-based approach for partitioning big spatial data in Hadoop, Elsevier Computers & Geosciences 106 (2017) 60–67 0098-3004/2017
14, Ahmed M. Aly, Ahmed R. Mahmood, Mohamed S. Hassan, Walid G. Aref, MouradOuzzani, HazemElmeleegy, ThamirQadah,2016, AQWA: Adaptive Query Workload Aware Partitioning of Big Spatial Data, . Proceedings of the VLDB Endowment, Vol. 8, No. 13, New Delhi,India
15, Ahmed EldawyLouaiAlarabi Mohamed F. Mokbel,2015, Spatial Partitioning Techniques in SpatialHadoop ,41st International Conference on VLDB,31/8 to 4/9 2015, Kohala Coast,Hawaii
16, Tin Vu,Alberto Belussi, Sara Migliorni, Ahmed Eldway,2020, Using Deep Learning for Big Spatial Data Partitioning , ACM Trans. Spatial Algorithms Syst., Vol. 1, No. 1, Article 1.
17, Qifa Ke, Vijayan Prabhakaran, Yinglian Xie, Yuan Yu,Jingyue Wu, Junfeng Yang,2011, Optimizing Data Partitioning for Data-Parallel Computing,HotOS
18, Amr Magdy, Louai Alarabi, Saif Al-Harthi, Mashaal Musleh,Thanaa M. Ghanem, Sohaib Ghani, Mohamed F. Mokbel,2014, Taghreed: A System for Querying, Analyzing, and Visualizing Geotagged Microblogs, SIGSPATIAL ’14, November 04-07 2014, Dallas/Fort Worth, TX, USA
19, SPARK, spark.apache.org, Last accessed 12/06/2022
20,DASK_GEOPANDAS, https://github.com/geopandas/dask-geopandas, , Last accessed 16/08/2022
up
|




