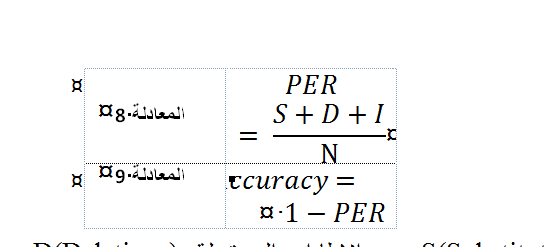
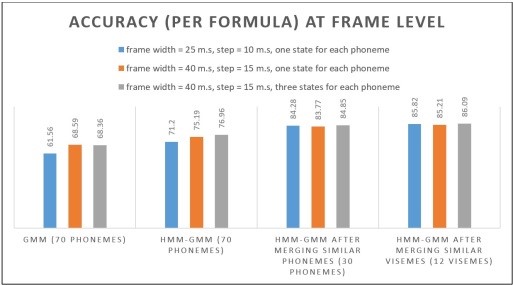
| |
المراجع
[1] C. Charalambous, Z. Yumak and A. F. van der Stappen, "Audio-driven emotional speech animation for interactive virtual characters," Computer Animation and Virtual Worlds, vol. 30, p. e1892, 2019.
[2] P. Edwards, C. Landreth, E. Fiume and K. Singh, "JALI: an animator-centric viseme model for expressive lip synchronization," ACM Trans. Graph., vol. 35, pp. 127:1-127:11, 2016.
[3] S. L. Taylor, M. Mahler, B.-J. Theobald and I. Matthews, "Dynamic Units of Visual Speech," in Proceedings of the ACM SIGGRAPH/Eurographics Symposium on Computer Animation, Goslar: DEU, Eurographics Association, 2012, p. 275–284.
[4] L. Wang, W. Han and F. Soong, "High quality lip-sync animation for 3D photo-realistic talking head," Acoustics, Speech, and Signal Processing, 1988. ICASSP-88., 1988 International Conference on, pp. 4529-4532, 2012.
[5] T. Ezzat, G. Geiger and T. Poggio, "Trainable Videorealistic Speech Animation," ACM Trans. Graph., vol. 21, p. 388–398, 2002.
[6] R. Anderson, B. Stenger and V. Wan, "Expressive Visual Text-To-Speech Using Active Appearance Models," Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2013.
[7] T. KARRAS, T. AILA, S. LAINE, A. HERVA and J. LEHTINEN, "Audio-Driven Facial Animation by Joint End-to-End Learning of Pose and Emotion," ACM Trans. Graph., vol. 36, p. 12, 2017.
[8] S. TAYLOR, T. KIM, Y. YUE, M. MAHLER, J. KRAHE, A. G. RODRIGUEZ, J. HODGINS and I. MATTHEWS, "A Deep Learning Approach for Generalized Speech Animation," ACM Trans. Graph., vol. 36, p. 11, 2017.
[9] Y. Chai, Y. Weng, L. Wang and K. Zhou, "Speech-driven facial animation with spectral gathering and temporal attention," Frontiers of Computer Science, 2021.
[10] B. Christoph, C. M. and S. Malcolm, "Video Rewrite: driving visual speech with audio," Proceedings of the 24th annual conference on Computer graphics and interactive techniques, 1997.
[11] T. Weise, S. Bouaziz, H. Li and M. Pauly, "Realtime Performance-Based Facial Animation," ACM Trans. Graph., vol. 30, p. 77, 2011.
[12] S. Ravikumar, "Performance Driven Facial Animation with Blendshapes," 2017.
[13] N. Halabi, "Modern standard Arabic phonetics for speech synthesis," p. 143, 2016.
[14] M. Antal, "SPEAKER INDEPENDENT PHONEME CLASSIFICATION IN CONTINUOUS SPEECH," Studia Universitatis Babeş-Bolyai. Informatica, vol. 49, 2004.
[15] G. Schwarz, "Estimating the Dimension of a Model," The Annals of Statistics, vol. 6, pp. 461 -- 464, 1978.
[16] A. Dempster, N. Laird and D. Rubin, "Maximum Likelihood from Incomplete Data Via the EM Algorithm," Journal of the Royal Statistical Society: Series B (Methodological), vol. 39, pp. 1-22, 1977.
[17] A. Viterbi, "Error bounds for convolutional codes and an asymptotically optimum decoding algorithm," IEEE Transactions on Information Theory, vol. 13, pp. 260-269, 1967.
[18] T. Larsson, m. and H. , "MakeHuman-Additions," 2020.
[19] P. Damien, N. Wakim and M. Egea, "Phoneme-viseme mapping for Modern, Classical Arabic language," in 2009 International Conference on Advances in Computational Tools for Engineering Applications, 2009, pp. {547-552.
[20] G. Bailly, "Learning to speak. Sensori-motor control of speech movements.," Speech Commun, vol. 22, pp. 251-267, 1997.
|