|
|
|
| |
م. إسلام كحيلان
د. ندى غنيم
د. عمار جوخدار
|
| |
الملخص
تقوم مهمة استخراج العلاقات Relation Extraction على إيجاد العلاقات الدلالية بين كيانات النص وتصنيفها حسب نوع العلاقة. تهدف هذه الورقة البحثية إلى استخراج العلاقات من النصوص العربية باستخدام الإشراف عن بعد Distance Supervision، بحيث قمنا في البداية بتجميع مجموعة المعطيات العربية ArRe24k بشكل آلي باعتماد الإشراف عن بعد، ليتم بعدها تدريب شبكة عصبونية التفافية متقطعة Piecewise Convolutional Neural Network (PCNN) مع طبقة انتباه على مستوى الجمل لتحديد وتصنيف العلاقات بين الكيانات الواردة في النصوص العربية، وتخطي أخطاء التنميط الآلي للبيانات الناتجة عن اعتماد الافتراض القوي للإشراف عن بعد. أظهر النموذج نتائج مقبولة بدقة (71.6%) على مجموعة المعطيات العربية المجمعة باعتماد التقييم اليدوي.
up
|
| |
Abstract
The task of relation extraction is to find semantic relations between text entities and classify them according to the type of the relation. This paper aims to extract relations from Arabic texts using Distance Supervision, so that we initially collected the ArRe24k Arabic corpus automatically by adopting the Distance Supervision methodology, then we trained Piecewise Convolutional Neural Network (PCNN) model with a sentence-attention layer, to detect and classify the relations between the mentioned entities in the Arabic texts and overcome the errors of automatic labeling caused by the strong assumption of Distance Supervision. The model on ArRe24k data showed acceptable results with accuracy (71.6%) using manual evaluation.
up
|
| |
المقدمة
يُفهم استخراج العلاقات باستخدام منهجية الإشراف عن بعد على أنه مهمة التنبؤ بالعلاقات المعبر عنها في النصوص المكتوبة باللغة الطبيعية. على سبيل المثال، في الجملة التالية "ومن الكتب الجامعة الشاملة في هذا الباب، كتاب سير أعلام النبلاء، للذهبي" يتم بدايةً الإشارة لزوج الكيان (سير أعلام النبلاء) و(الذهبي)، ليقوم بعدها نظام استخراج العلاقات بأخذ زوج الكيان الذي تم ترشيحه وتحديد العلاقة الدلاليّة بين زوج الكيان ضمن سياق الجملة المُعطى. فمثلاً في المثال السابق يتنبأ نظام استخراج العلاقات الجيّد بعلاقة (مؤلف).
نظراً للدور المهم الذي تلعبه الموارد اللغوية في أداء مهام استخراج العلاقات، ونظراً لكون التحدي الأكبرً هو نقص هذه الموارد، خاصة بالنسبة للغات ضعيفة الموارد كاللغة العربية، ونظراً لارتفاع التكلفة الزمنية والمادية الخاصة ببناء مثل هذه الموارد بشكل يدوي وبوجود خبراء لغويين، ظهر مفهوم الإشراف عن بعد Distance Supervision [1]، والذي يمكن باعتماده العمل على إنشاء مثل هذه الموارد بزمن وكلفة أقل.
تستخدم منهجية الإشراف عن بعد لإعداد بيانات تدريب منمطة آلياً باعتماد قواعد المعرفة Knowledge base من دون الحاجة إلى تدخل بشري، ويقوم على مبدأ الاستفادة من الكم الهائل للنصوص غير المنمطة والتي يمكن اعتبارها مصادر غنية ومتنوعة لتكوين الموارد اللغوية، إلى جانب قواعد المعرفة المتاحة، بحيث تتم عملية معالجة مسبقة لتلك النصوص باستخدام أداة تعرف الكيانات الاسمية Named Entity Recognition لتحديد أزواج الكيانات في جمل النص، ثم يجري البحث عن العلاقات التي تربط بين هذه الأزواج ضمن قاعدة المعرفة المعتمدة. على سبيل المثال، تحتوي قاعدة المعرفة DBpedia على حقيقة أن خير الدين الزركلي توفي في مصر، فيتم أخذ هذه الحقيقة واعتبار جميع الجمل التي يظهر بها زوج الكيان "الزركلي" و"مصر" كمثال إيجابي لعلاقة "مكان الوفاة".
بالنسبة للأبحاث القائمة على اللغة الإنكليزية والتي اعتمدت أسلوب الإشراف عن بعد كوسيلة لاستخراج العلاقات، فقد قام أغلبها باستخدام مجموعة المعطيات المنمطة آليّاً في [2]، والتي أصبحت بمثابة مجموعة معطيات مرجعية لأغلب الأبحاث التي اعتمدت الإشراف عن بعد. بالمقابل، افتقرت اللغة العربية لوجود مثل مجموعة المعطيات المرجعية هذه والتي توفر قاعدة ثابتة تمكّن الباحثين من مقارنة أعمالهم مع بعضهم البعض.
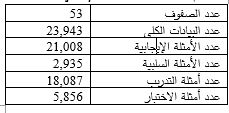
تتمثل مساهمة هذه الورقة باقتراح منهجية الإشراف عن بعد لبناء مجموعة المعطيات ArRe24k العربية لمهام استخراج العلاقات، بحيث جرى تطبيق المنهجية على نصوص ويكيبيديا العربية إلى جانب قاعدة المعرفة DBpedia، ونتج عنها مجموعة معطيات تضمنت 23,943 مثالاً موزعة على 53 نوع علاقة، منها 18,087 مثال تدريب، و 5,856 مثال اختبار.
نقوم في المقطع التالي بعرض لمحة عامة عن الأعمال السابقة، ثم شرح مفصل لمنهجيتنا، وبعد ذلك مناقشة للنتائج التجريبية على مجموعة المعطيات ArRe24k ومقارنتها مع الأعمال الأخرى، وفي النهاية نعرض خاتمة تستعرض آفاقاً مستقبلية للعمل.
up
|
| |
الأبحاث السابقة
يتعلم المصنف في ضوء الإشراف عن بعد على مجموعة تدريب ذات تنميط ضعيف، بحيث يتم تجميع بيانات التدريب آلياً، وبالتالي تكون مجموعة المعطيات التي تم تجميعها تعاني من مشكلة التنميط الخاطئ لذلك يأخذ هذا المنهج بعين الاعتبار القدرة على تخطي هذه المشكلة وجعل المصنف قادراً على التعلم على تلك البيانات بشكل جيد رغم الخطأ الموجود ضمن بيانات التدريب. من الأعمال التي تمت ضمن هذا المنهج ما قام به كل من ]3، 4، 5، 6[.
العديد من الأعمال القائمة على نصوص اللغة الإنكليزية والتي اتبعت منهجية الإشراف عن بعد مثل ]5، 6، 7، 8، 9، 10، 11، 12، 13[ اعتمدت على عمل Riedel et al. [2] الذي قام ببناء مجموعة المعطيات New York Times (NYT) للغة الإنكليزية بشكل آلي، وأصبحت كمرجع للعديد من أعمال استخراج العلاقات باستخدام الإشراف عن بعد. على عكس اللغات ضعيفة الموارد، مثل العربية، والتي نشهد فيها نقصاً في الأبحاث المقدمة في مجال استخراج العلاقات. تنقسم الأبحاث المقدمة في اللغة العربية إلى الأبحاث المعتمدة على القواعد كما فعل كل من [14، 15، 16]، الأبحاث التي اعتمدت الأساليب غير الخاضعة للإشراف مثل [17]، والأبحاث التي اعتمدت على الأسلوب الخاضع للإشراف [18]، وأخيراً الأبحاث المعتمدة على الإشراف عن بعد مثل [19].
الافتراض القوي للإشراف عن بعد الذي يقول بأن جميع الجمل التي لها نفس زوج الكيان، فإنها بالضرورة تعبّر عن نفس العلاقة التي تربط زوج الكيان هذا داخل قاعدة المعرفة، يجعل من مجموعة المعطيات المجمّعة تعاني من مشكلة الأمثلة ذات التنميط الخاطئ. للتغلب على هذه المشكلة، يتم استخدام التعلم متعدد الأمثلة multi-instance learning على نطاق واسع في استخراج العلاقات والذي يقوم على مبدأ تجميع الأمثلة التي تتشارك بذات الكيانين وتربطها ذات العلاقة ضمن حقيبة واحدة، واعتماد تمثيل الحقيبة بدلاً من تمثيلات الجمل المكونة لها. يتم تطبيق التعلم متعدد الأمثلة بطرق مختلفة مثل "فرضية واحدة على الأقل" at least one hypothesis التي طبقهاZeng et al. في [13]، والتي تقوم على أخذ جملة واحدة، وهي الجملة التي تمثل العلاقة بشكل أكبر، من كل حقيبة واعتماد تمثيل هذه الجملة على أنه التمثيل الخاص بالحقيبة ككل. هذه الطريقة لا تستفيد من الكم الكبير لبيانات التدريب كونها تأخذ مثالاً واحداً فقط من كل حقيبة، لذلك قام كل من [10، 20] بأخذ جميع الجمل ضمن الحقيبة بعين الاعتبار للحصول على التمثيل الخاص بالحقيبة وذلك من خلال إعطاء كل جملة وزناً يمثل مدى قربها من التمثيل الخاص بالعلاقة الهدف. في حين جرى في [5] تمثيل الحقيبة بطريقة مدركة للعلاقة من خلال حساب مدى قرب الجملة من جميع العلاقات وليس فقط من العلاقة الهدف. أما [21] فقد استخدم شبكة عصبونية بيانية Graph Neural Network لفلترة الجمل ذات التصنيف الخاطئ ضمن الحقيبة.
بالنسبة للأبحاث التي تمت باللغة العربية، فهناك دراسة وحيدة قام بها Mohamed et al. [19] باستخدام الإشراف عن بعد على النصوص العربية، ولكنه لم يأخذ ضجيج بيانات التدريب بعين الاعتبار وتم تدريب المصنف على مجموعة المعطيات كما لو كانت مجموعة معطيات منمطة بطريقة يدوية وتخلو من مشاكل التنميط الخاطئ.
في هذا العمل تم استخدام النموذج الخاص بعمل [13] لتطبيقه على مجموعة المعطيات ArRe24k العربية، وإعطاء مقارنة تقريبية بين مجموعة المعطيات ArRe24k المجمعة من قبلنا ومجموعة المعطيات الإنكليزية المزودة من قبل Riedel et al. [2] والتي استخدمها [13] في عمله لتدريب النموذج الخاص به، واعتماد التعلم متعدد الأمثلة مع فرضية "واحدة على الأقل" لتخطي مشكلة التنميط الخاطئ.
3 المنهجية المقترحة
تتضمن المنهجية المقترحة جزأين رئيسيين: يشمل الجزء الأول بناء مجموعة المعطيات ArRe24k العربية باستخدام منهجيّة الإشراف عن بعد، بينما يشمل الجزء الثاني تدريب نموذج شبكة عصبونية التفافية متقطعة Piecewise Convolutional Neural Network (PCNN) مع طبقة انتباه على مستوى الجمل لتقييم قدرة النموذج على التدرب وتخطي ضجيج بيانات تدريب مجموعة المعطيات المجمّعة ArRe24k. وفيما يلي وصف مفصل لكل جزئية على حدة.
1.3 مجموعة المعطيات ArRe24k
تم بناء مجموعة المعطيات باستخدام الإشراف عن بعد والذي يتطلب مصدرين لغويين أساسيين لبناء مدونة منمطة بشكل آلي، وهما النصوص الخام المراد تنميطها وقد تم استخدام نصوص الويكيبيديا العربية لهذه المهمة، وقاعدة معرفة مناسبة لربط الكيانات الواردة ضمن النصوص الخام مع ورودها ضمن قاعدة المعرفة لاستنتاج العلاقات التي تربط بينها ضمن هذه القاعدة، وقد تم استخدام DBpedia العربية كقاعدة معرفة، وهي أنطولوجيا تعتمد على صناديق المعلومات Infoboxes الأكثر استخداماً في ويكيبيديا [22]. يحتوي إصدار 10-2016 المستخدَم على 487,874 ثلاثية من النمط (>الموضوع<subject | >خاصية<property | >الكائن |<object )، تتضمن 495 خاصية مختلفة، و124,609 موضوعاً، و234,711 كائناً. يمثل الموضوع والكائن زوج الكيان المختار، وتمثل الخاصية العلاقة الرابطة بينهما ضمن قاعدة المعرفة.
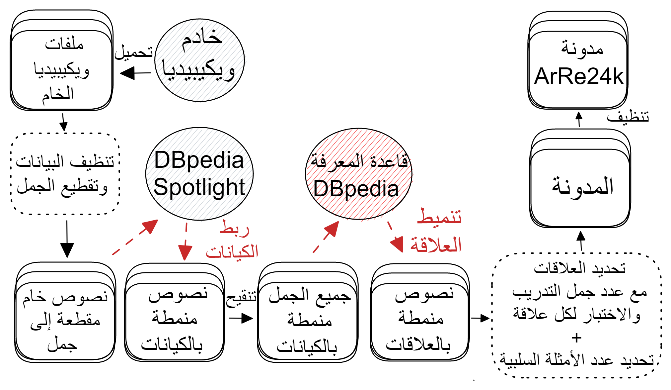
رسم توضيحي 1 المراحل المتبعة لإنشاء مدونة ArRe24k.
يعرض الشكل 1 المراحل المتبعة لإنشاء مجموعة المعطيات ArRe24k، بحيث تم في البداية تنقيح نصوص الويكيبيديا من الروابط، والترجمات، وملفات الوسائط. ليتم بعدها تقطيع النصوص إلى جمل باعتبار أن الجملة تنتهي بنقطة. ثم تم تحديد الكيانات الواردة ضمن النصوص باستخدام DBpedia Spotlight، ليتم البحث عن العلاقة التي تربط بين كل كيانين متتاليين في الجمل، ضمن قاعدة المعرفة DBpedia، باستخدام الروابط المزودة من قبل هذه الأداة بدلاً من الكلمات الممثلة للكيان كوسيلة لفك الغموض الخاص بالكيان.
على سبيل المثال، في الجملة التالية "ودفن فريدرش فيلهلم الثالث في الضريح في شلوسبارك شارلوتنبورغ، برلين." تم تحديد الكيان الأول من قبل DBpedia Spotlight على أنه (فريدرش فيلهلم الثالث)، وتحديد الكيان الثاني على أنه (برلين)، وتحديد العلاقة الدلاليّة بين زوج الكيان ضمن قاعدة المعرفة DBpedia على أنها (مكان الوفاة). بعد ذلك قمنا بأخذ أكثر 52 علاقة تحتوي على جمل من أصل 198 علاقة، وأضفنا لها علاقة NA (لايوجد علاقة) بحيث تمثل الجمل التي تضم كيانيين ولا تربطهما أية علاقة، كوسيلة لإدخال الأمثلة السلبية. تم أخذ 75% من الجمل الخاصة بكل علاقةا للتدريب و 25% للاختبار. لتحديد عدد الأمثلة في الصف المرتبط بعدم وجود علاقة، جرى الاعتماد على دراسة Cernazanu-Glavan et al. [23] والتي أوصت بأن يكون عدد الأمثلة في هذا الصف 16% من مجمل عدد الجمل الإيجابية ككل (الجمل التابعة لجميع العلاقات، وعددها 52). تم تنظيف مجموعة المعطيات بالاستعاضة عن الأرقام الإنكليزية والعربية بكلمة (NB)، والاستعاضة عن علامات الترقيم الإنكليزية بأخرى عربية، كما تم حذف الأقواس بالإضافة إلى العبارات الواردة ضمنها، وحذف جميع المحارف الأجنبية وإبقاء المحارف العربية فقط.
تضمنت مجموعة المعطيات 23,943 مثالاً، منها 18,087 مثال تدريب، و 5,856 مثال اختبار. يوضح الجدول 1 معلومات مفصلة عن حجم مجموعة المعطيات التي تم تجميعها.
الجدول 1 حجم مجموعة المعطيات العربية في مدونة ArRe24k.
2.3 النموذج المنفذ
تم استخدام النموذج الخاص بـ Zeng et al. [13] لتدريبه على مجموعة المعطيات ArRe24k بغرض التعلم الآلي للسمات من دون الحاجة إلى استخراج سمات عالية المستوى بواسطة أدوات معالجة اللغات الطبيعية بحيث تم اعتماد نموذج شبكة PCNN يستقبل كدخل مجموعة جمل تم تمثيل كل كلمة فيها بمتجه يحتوي تضمين الكلمة وتضمين موقعها، ليتنبأ بالعلاقة الدلاليّة الممثلة لكل جملة. كما تم تطبيق التعلم متعدد الأمثلة باستخدام فرضية "واحدة على الأقل" للتعامل مع التنميط الخاطئ. النموذج المستخدم هو ذاته نموذج [13]، ولكن يختلف عنه بنموذج تضمين الكلمة وحجم نافذة تضمين الكلمة، حيث تم اعتماد نموذج التضمين Aravec مفتوح المصدر [24] واختيار النموذج Skipgram المدرب مسبقاً، بطول نافذة 300، مع طول جملة يتضمن 70 كلمة.
يعرض الشكل 2 بنية النموذج، ويوضح كيفيّة استخراج خصائص الجملة والحقيبة، والتنبؤ بالعلاقة بين زوج الكيان (عبد العظيم أنيس) و(القاهرة) ضمن سياقين مختلفين.
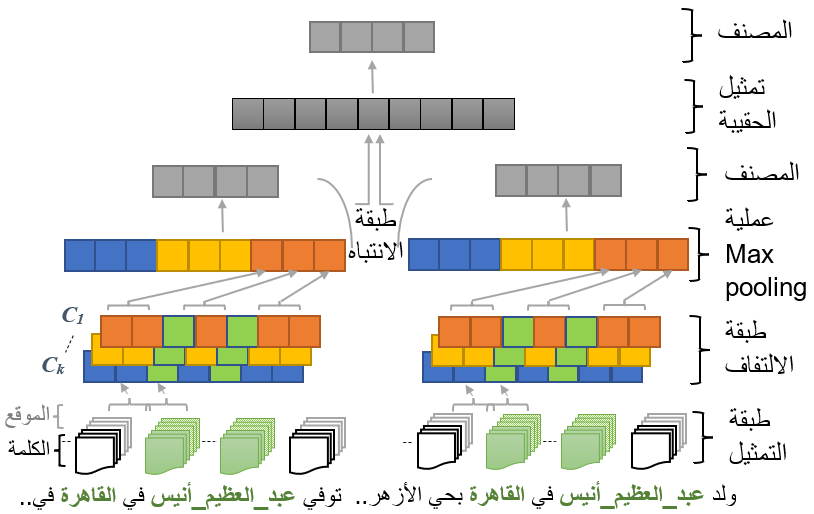
رسم توضيحي 2 بنية النموذج المستخدم لمهمة استخراج العلاقة يوضح كيفية تشكيل خصائص الجمل والحقائب.
1.2.3 طبقات النموذج
كما هو موضح بالشكل 2 يتضمن النموذج المستخدم 4 طبقات رئيسية (1) طبقة التمثيل Representation حيث يكون تمثيل المتجه لكل كلمة عبارة عن التضمين الخاص بالكلمة والتضمين الخاص بموقعها. (2) طبقة الالتفاف Convolution التي تعمل على بناء تمثيل للمتجه المدخل يراعي سياق الجملة. (3) عملية Max-pooling والتي تعمل على إنشاء متجه بطول ثابت يقدم أفضل تلخيص لتمثيل الجملة، بحيث يتم جعل التمثيل مستقلاً عن طول الجملة. يتم هنا تقسيم الجملة إلى ثلاثة أجزاء بناءً على مكان الكيانين، جزء الجملة الذي يقع قبل الكيان الأول، وجزء الجملة الذي يقع بين الكيانين، وجزء الجملة الذي يقع بعد الكيان الثاني، ثم تقديم أفضل تلخيص لكل جزئية على حدة. (4) طبقة الانتباه على مستوى الجملة sentence-level attention التي تتعامل مع ضجيج بيانات التدريب، بحيث تتبع هذه الطبقة فرضية "على الأقل واحدة" لتحديد جملة واحدة من الحقيبة المعنية والتي من المرجح كونها أكثر جملة تمثل العلاقة المستهدفة، ومن ثم أخذ تمثيلها على أنه التمثيل الخاص بالحقيبة ككل، ليتم التنبؤ بالعلاقة على مستوى الحقيبة وتحديث معاملات الشبكة بناءً عليها.
4 النتائج
قمنا بمجموعة من التجارب شملت مقارنة مجموعة المعطيات العربية ArRe24k والمجمّعة آلياً بواسطة الإشراف عن بعد، مع مجموعة معطيات إنكليزية وأخرى عربية مجمّعة بشكل آلي أيضاً. بالنسبة لمجموعة المعطيات الإنكليزية جرى اختيار مجموعة معطيات NYT [2] ومقارنة حجم البيانات ونتائج تطبيق ذات النموذج وذات آلية إزالة الضجيج على كلا المدونتين. أمّا بالنسبة لمجموعة المعطيات العربية فقد جرى اختيار مجموعة المعطيات ArabRelat [19].
لتقييم الأداء، تم استخدام التقييم اليدوي على أفضل N جملة، والذي يُظهر دقة تنبؤ النموذج precision مع الأخذ في الاعتبار التنميطات اليدوية الصحيحة بدلاً من التنميطات الآلية الناتجة عن تطبيق الإشراف عن بعد، إذ يوضح التقييم اليدوي الفرق بين تنبؤ النموذج وبين التنميط البشري، كما يعطي فكرة عن قدرة النموذج على تخطي الضوضاء والتعامل مع أخطاء البيانات، وبالتالي يوضح إمكانية النموذج على جعل تنبؤاته أقرب إلى الواقع (التنميطات البشرية) باستخدام الآلية المقترحة لإزالة الضجيج.
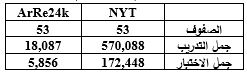
1.4 مقارنة مجموعة المعطيات ArRe24k العربية مع مجموعة المعطيات NYT الإنكليزية
من الجدول 2 وبمقارنة حجم مجموعة المعطيات ArRe24k العربية، و NYT الإنكليزية، بحيث تحتوي كلاهما على 53 صفاً، نجد أن مجموعة المعطيات NYT تحتوي على 570,088 مثال تدريب، و172,448 مثال اختبار، مقابل 18,087 مثال تدريب، و5,856 مثال اختبار لمجموعة ArRe24k. أي أن مجموعة المعطيات العربية أقل بـ 522,001 مثال تدريب عن مجموعة المعطيات الإنكليزية.
الجدول 2 مجموعة المعطيات الإنكليزية (NYT)، مقارنة بالعربية (ArRe24k).
هذا الفارق الكبير في حجم مجموعة المعطيات سيؤثر بشكل كبير على قدرة النموذج على التدرب أولاً، وتخطي الضوضاء ثانياً، ذلك لأن عدد الحقائب التي يتم تشكيلها بالنسبة لمجموعة معطيات اللغة الإنكليزية أكثر من الحقائب التي يتم تشكليها في مجموعة معطيات اللغة العربية بناءً على عدد عينات التدريب المتاحة لكل لغة، وبالأخذ بعين الاعتبار أنه سيتم أخذ جملة واحدة من جميع الجمل الممثلة لكل حقيبة، فإن عدد بيانات التدريب سيكون حاسماً في تحديد قدرة النموذج على التعلم وتجاوز أخطاء التنميط.
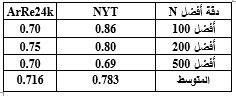
الجدول 3 مقارنة نتائج دقة التقييم اليدوي لكل مدونة.
هذا الأمر يظهر واضحاً في الجدول 3 الذي يقارن نتائج الدقة لأفضل 100 و 200 و 500 جملة باستخدام التقييم اليدوي على كلتا المدونتين، بعد تطبيق نموذجZeng et al. [13] لدراسة قدرة شبكة PCNN على التدرب والتغلب على الضوضاء لكل مجموعة باستخدام التعلم متعدد الأمثلة بفرضية "واحدة على الأقل".
أظهرت النتائج متوسط دقة 71,6% على مجموعة المعطيات العربية، مقابل 78.3% على مجموعة المعطيات الإنكليزية، أي هناك انخفاض في الدقة على مجموعة المعطيات ArRe24k العربية بنسبة 6.7%.
2.4 مقارنة مجموعة المعطيات ArRe24k مع مجموعة المعطيات ArabRelat
لمقارنة مجموعة المعطيات ArRe24k العربية مع مجموعة معطيات عربية أخرى تم تجميعها أيضاً بطريقة آلية باستخدام الإشراف عن بعد، تم اعتماد Mohamed et al. [19] الذي استخدم الأسلوب القائم على السمات Feature-based methods واعتمد 16 سمة لتدريب مصنف SVM على مجموعة المعطيات ArabRelat العربية. اعتمدنا في بحثنا على التعلم العميق باستخدام نموذج شبكة PCNN مع طبقة انتباه على مستوى الجملة لتجاوز ضجيج بيانات تدريب ArRe24k، كما تم الاعتماد على تضمين الكلمة والموقع فقط لتمثيل مدخلات النموذج.
الجدول 4 مجموعة المعطيات ArabRelat، مقابل مجموعة المعطيات ArRe24k، مع مقارنة الدقة الناتجة عن التقييم اليدوي لكل مدونة.
يعرض الجدول 4 معلومات حول مجموعة المعطيات ArabRelat والتي تشمل 4,915 عينة تدريب موزعة على 98 صف، مقابل 18,087 عينة تدريب ضمن مجموعة المعطيات ArRe24k وموزعة على 53 صف، هذا يعني 13,172 عينة إضافية ضمن مجموعة المعطيات ArRe24k.
بمقارنة بين دقة نموذج PCNN على مجموعة المعطيات ArRe24k لحوالي 100 جملة باستخدام التقييم اليدوي (70%) مع دقة SVM على مجموعة المعطيات ArabRelat (50%)، نجد أن النموذج الخاص بنا تفوق بمقدار 20% على النموذج الخاص بـ ArabRelat. ذلك لأنه في مسائل التصنيف متعدد الصفوف multi-class classification يجب توفير عدد عينات تدريب جيد لكل صف، ولكن بالنظر لعدد عينات التدريب في ArabRelat فإنّ عدد العينات المزوّد قليل مقابل عدد الصفوف التي تم أخذها بعين الاعتبار. بالإضافة إلى ذلك، فإن ArabRelat تجاهل تماماً المشكلة الأساسية لمجموعة المعطيات المجمّعة بواسطة الإشراف عن بعد وهي التنميط الخاطئ لبعض الجمل الناتج عن الافتراض القوي للإشراف عن بعد. معنى ذلك، أن النموذج يمكن أن يقدم أداءً لا بأس به في حال تم أخذ التقييم الآلي من نمط Held-out evaluation والذي يقارن توقعات النموذج مع التنميط الخاص بالإشراف عن بعد، والذي أعطى دقة مساوية 74% على أفضل 100 جملة من بيانات ArabRelat، وأعطى دقة مساوية 93% على أفضل 100 جملة من بيانات ArRe24k، ولكن هذه الدقة حتماً لا تعبر عن الأداء الواقعي للنموذج. على سبيل المثال، في الشكل 2 يوجد جملتين تم تحديد العلاقة الدلالية لهما ضمن بيانات ArRe24k على أنها (مكان الولادة). تم تنميط الجملة الأولى "ولد عبد_العظيم_أنيس في العاصمة المصرية القاهرة بحي الأزهر .." بشكل صحيح، وتعبر عن علاقة مكان الولادة بين الكيانين (عبد العظيم أنيس) و(القاهرة)، أما الجملة الثانية " توفي عبد_العظيم_أنيس في القاهرة في يناير .." فتم تحديد العلاقة على أنها مكان الولادة بين ذات زوج الكيان رغم أنّ الجملة هنا تعبر عن مكان الوفاة. في التقييم الآلي المستخدم، سيتم اعتبار أن النموذج تنبأ بالعلاقة بين زوج الكيان في كلتا الجملتين بشكل صحيح في حال تم تحديد العلاقة على أنها مكان الولادة، بينما يعتبر التقييم اليدوي أن النموذج قد تنبأ بالعلاقة بين زوج الكيان بشكل صحيح في حال تم تحديد العلاقة التابعة للجملة الأولى على أنها مكان الولادة، بينما تم تحديد العلاقة التابعة للجملة الثانية على أنها مكان الوفاة.
up
|
| |
الخاتمة
قدمنا في هذه الورقة منهجية باعتماد الإشراف عن بعد لإنشاء مجموعة المعطيات ArRe24k العربية بهدف استخراج العلاقات من الكيانات الواردة في النص، وتزويد نموذج قادر على التدرب على هذا النوع من البيانات والتعامل مع التنميط الخاطئ لبعض جملها والناتج عن الافتراض القوي للإشراف عن بعد. تظهر التقييمات نتائج مقبولة بمتوسط دقة 71.6% باستخدام التقييم اليدوي على أفضل 100، 200، 500 جملة من بيانات الاختبار. نطمح في المستقبل إلى زيادة حجم مجموعة المعطيات مع القيام بعدة تحليلات إحصائية عليها وتجربة مجموعة من النماذج المختلفة مع طرائق مختلفة للتعامل مع ضجيج البيانات الوارد بها.
up
|
| |
Reference
[1] Mintz, Mike, et al. "Distant supervision for relation extraction without labeled data." Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP. 2009.
[2] Riedel, Sebastian, Limin Yao, and Andrew McCallum. "Modeling relations and their mentions without labeled text." Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, Berlin, Heidelberg, 2010.
[3] Li, Weijiang, et al. "Piecewise convolutional neural networks with position attention and similar bag attention for distant supervision relation extraction." Applied Intelligence 52.4 (2022): 4599-4609.
[4] Wang, Jiasheng, and Qiongxin Liu. "Distant supervised relation extraction with position feature attention and selective bag attention." Neurocomputing 461 (2021): 552-561.
[5] Ye, Zhi-Xiu, and Zhen-Hua Ling. "Distant supervision relation extraction with intra-bag and inter-bag attentions." arXiv preprint arXiv:1904.00143 (2019).
[6] Zhou, Yanru, et al. "Self-selective attention using correlation between instances for distant supervision relation extraction." Neural Networks 142 (2021): 213-220.
[7] Chen, Jing, Zhiqiang Guo, and Jie Yang. "Distant Supervision for Relation Extraction via Noise Filtering." 2021 13th International Conference on Machine Learning and Computing. 2021.
[8] Chen, Tiantian, et al. "Distant supervision for relation extraction with sentence selection and interaction representation." Wireless Communications and Mobile Computing 2021 (2021).
[9] Christou, Despina, and Grigorios Tsoumakas. "Improving distantly-supervised relation extraction through bert-based label and instance embeddings." IEEE Access 9 (2021): 62574-62582.
[10] Ji, Guoliang, et al. "Distant supervision for relation extraction with sentence-level attention and entity descriptions." Thirty-First AAAI Conference on Artificial Intelligence. 2017.
[11] Meng, Xiaoyan, et al. "Improving distant supervised relation extraction with noise detection strategy." Applied Sciences 11.5 (2021): 2046.
up
|
| |
|
| |
|
|




