|
|
|
| |
م. رهف الشريف
د. ندى غنيم
د. أميمة الدكاك
|
| |
الملخص
تهدف مهمة تصنيف المشاعر المتعددة الفئات إلى تحديد جميع المشاعر المحتملة في نص مكتوب يمثل الحالة العقلية للكاتب للحصول على أفضل أداء، كما تحاول فهم تعبيرات الشخص وعواطفه في النص، بما في ذلك مشاعر (الحزن، والغضب، والاشمئزاز، والمفاجأة، الخوف والفرح ....). في السنوات الأخيرة، اجتذبت مشكلة تصنيف المشاعر المتعددة الفئات انتباه الباحثين لأهمية تطبيقاتها المحتملة في التعليم الإلكتروني والرعاية الصحية والتسويق وما إلى ذلك. نظراً لوجود حاجة لطريقة قياسية لتطوير وتقييم أساليب تصنيف المشاعر المتعددة الفئات، من أجل توفير نموذج يتم تضمينه في تطبيقات تركيب الكلام على سبيل المثال؛ نركز في هذا البحث على مفهوم تحليل وتحديد المشاعر المستخرجة من الجمل المكتوبة باللغة العربية الفصحى والتي تم تنميطها إلى 11 فئة من المشاعر في النص وهي: (الغضب، الفرح، الحزن، المفاجأة، الاشمئزاز، الترقب، الحب، التشاؤم، الخوف، التفاؤل، الثقة). اعتمدت هذه الدراسة على مجموعة بيانات مهمة لتصنيف المشاعر المتعددة الفئات وهي SemEval-2018 Task 1: (AIT-2018) حيث تم جمع معظم النصوص المتعلقة باللغة العربية من وسائل التواصل الاجتماعي وغالباً ما كانت اللهجة المستخدمة هي اللهجة العامية. ولما كان هدفنا تصنيف المشاعر باللغة الفصحى، فقد قمنا ببناء مدونة MLArEC-1 تحوي جملاً عربية فصحى منمطة بالمشاعر (4381 جملة)، ثم قمنا بتوسعتها بنسخة MLArEC-2 (5645 جملة)، طبقنا طرقاً قائمة على التعلم بالنقل(Transfer Learning) اعتماداً على نماذج BERT للغة العربية مثل (BERTBASE, ARBERT, MABERT) على مجموعة البيانات المقترحة التي أعددناها. وقد أجرينا مجموعة مكثفة من التجارب وحصلنا على أفضل النتائج باستخدام MABERT بحجم دفعة (Batch-Size) تساوي 32 و10 عصور تدريب (Epochs) بمعدل Micro-F1 يساوي 0.94.
up
|
| |
كلمات مفتاحية
تحليل المشاعر، التصنيف متعدد الفئات، MSA، المحولات (Transformers)، نماذج BERT.
up
|
| |
Abstract
The multi-label emotion classification task aims to identify all possible emotions in a written text that best represent the person's mental state. It tries to understand his expressions and emotions in the text, including feelings (sadness, anger, disgust, surprise, fear, joy, ....). Recently, multi-label emotion classification MLEC attracted the attention of researchers due to its potential applications in e-learning, healthcare, marketing, etc. As we aim to integrate this system in a speech synthesis application, our work will be on Standard Arabic sentences. We study 11 emotions, namely: (anger, joy, sadness, surprise, disgust, anticipation, love, pessimism, fear, optimism, confidence). This work is based on SemEval-2018 dataset for the multi-label emotion classification task “Affect In Twitter” (AIT). Most of this dataset (Arabic section) were collected from social media where dialect is used and since our goal is to classify emotions in MSA language, we built an MSA dataset annotated with emotion MLArEC-1 containing 4,381 sentences, then expanded it with a MLArEC-2 version having 5645 sentences. We applied BERT-based Transfer Learning- method using Arabic pretrained models (BERTbase, ARBERT, MABERT) on our proposed dataset. We conducted an extensive set of experiments and obtained the best results using MABERT with batch size equal to 32 and 10 training epochs and the Micro-F1 rating is 0.94.
up
|
| |
المقدمة
قد يحتوي جزء من النص على واحد أو أكثر من أنواع المشاعر، وتهدف مهمة تصنيف المشاعر الأحادية الفئة إلى توقع عاطفة واحدة فقط في النص. لكن يتمثل العيب الرئيسي لنظم تصنيف المشاعر الأحادية الفئة في أنها لا تلتقط سوى عاطفة واحدة في نص معين، مما يجعل من الصعب فهم الحالة العاطفية للشخص تماماً. ونظراً لما سبق فقد تمَّ تركيز الجهود على تصنيف المشاعر المتعددة الفئات من أجل التغلب على هذا القيد من خلال التقاط جميع المشاعر الممكنة. تركز نماذج تحليل المشاعر على تحليل وتحديد المشاعر المختلفة في الجمل مثل: مشاعر (الغضب، الفرح، الحزن، المفاجأة، الاشمئزاز، ...) وسيتم التركيز في هذا البحث على المسائل التي تحوي جملاً فيها أكثر من شعور واحد وهذا ما يدعى بدراسة مسألة تصنيف الجمل المتعددة التسميات أو مسألة تصنيف الجمل المتعددة الفئات. لتصنيف المشاعر المتعددة الفئات تطبيقات محتملة في مجالات عدة منها: أنظمة تركيب الكلام ونظم تحليل المحادثات، أو جمع الآراء حول رواية معينة أو حوار معين أو لقياس رضى الزبائن حول منتج معين. يدرس هذا البحث اكتشاف المشاعر المختلفة المستخرجة من الجمل المكتوبة باللغة العربية الفصحى والتي تمَّ تنميطها إلى 11 فئة من المشاعر في النص وهي: (الغضب، الفرح، الحزن، المفاجأة، الاشمئزاز، الترقب، الحب، التشاؤم، الخوف، التفاؤل، الثقة). اعتمد العمل في هذه الورقة على مجموعة بيانات لمهمة تصنيف المشاعر المتعددة الفئات وهي SemEval-2018 Task1 (AIT- 2018) والتي تمَّ فيها جمع النصوص من وسائل التواصل الاجتماعي وهي بالتالي باللهجة العامية، ولما كان هدفنا البعيد هو ربط النظام مع نظام تركيب كلام باللغة العربية الفصحى، فقد قمنا بتحويلها يدوياً إلى الفصحى، وبلغ عدد الجمل (5645 جملة). طبقنا طرقاً قائمة على التعلم بالنقل والتي بنيت اعتماداً على النسخ العربية من نماذج BERT مثل (BERTBASE ARBERT, MABERT) وهذه النسخ هي بالترتيب ("asafaya/bert-base-arabic","UBC-NLP/ARBERT","UBC-NLP/MARBERT") وقد قمنا بمقارنة دقة هذه النظم على مجموعة البيانات المقترحة. تم تنظيم بقية هذه الورقة على النحو التالي: يعرض المقطع الثاني الأعمال السابقة المنجزة في هذا المجال فيما يخص اللغتين الإنكليزية والعربية. ويشرح المقطع الثالث عملية تجميع المدونات المستخدمة لإنشاء المجموعة المقترحة. ويبين المقطع الرابع المنهجية المستخدمة، أما المقطع الخامس فيعرض تحليل النتائج. أخيرا، يختتم القسم السادس الورقة ويناقش الآفاق المستقبلية للعمل.
up
|
| |
الأعمال السابقة
يدخل مكون "تعرف المشاعر" من النصوص في العديد من التطبيقات، مما ساهم في وجود العديد من الأبحاث التي تعمل في هذا الإطار. سنستعرض في هذا القسم مجموعة من الأبحاث التي تخص تعرف المشاعر بالنصوص الإنكليزية، ثم نستعرض ما جرى من أبحاث في اللغة العربية.
A. الأعمال ذات الصلة باللغة الإنكليزية
اعتمد الباحثون (Ying, et al., 2019) على قاعدة بيانات task1(AIT-2018) Ec SemEval- في محاولة لاكتشاف المشاعر المتعددة الفئات وقد حقق النموذج قيمة 71.6 على مقياس F1 باستخدام BERT. اعتمد الباحثون (Jabreel & Moreno, 2019) على قاعدة البيانات المشار لها سابقاً وباستخدام الشبكات العصبونية التكرارية RNN وطبقتي FFN مع تابع التنشيط Relu وSigmoid مع تابع التحسين Adam (Adam, et al., 2017) وحجم دفعة 32 من أجل تقليل قيم BCE فكانت دقة النتائج باستخدام مقياس Jaccard Index تساوي 0.95 وحقق قيمة باستخدام مقياس F1 تساوي 0.692.أيضاً اعتمد الباحثون (Iqra, et al., 2020) على قاعدة البيانات المشار لها سابقاً وتمَّ تحقيق أفضل النتائج باستخدام word-unigram ومصنفات Random Forest (RF) من أجل كل فئة من فئات المشاعر وmulti-label Binary Relevance من أجل فئات المشاعر وكانت قيمة مقياس F1 تساوي 0.573أما قيمة الدقة Accuracy فكانت 0.452. كما قام الباحثون (Alhuzali & Ananiadou, 2021) بالعمل على ذات المدونة السابقة وقد كانت قيمة مقياس F1 تساوي 0.746 باستخدام BERT وذلك بالاعتماد على حساب تابع (LCA) وتابع (BCE) أثناء التدريب. اعتمد الباحثون (Iqra, et al., 2022) على تصنيف الرسائل النصية المكتوبة باللغتين الإنجليزية والرومانية حيث أن كل رسالة منمطة يدوياً إلى 12 نوع من المشاعر بما في ذلك الغضب والترقب والاشمئزاز، والخوف، والفرح، والحب، والتفاؤل، والتشاؤم، والحزن، والمفاجأة، والثقة، والحيادية. قاموا بتطبيق ومقارنة أحدث تقنيات التعلم الآلي (content-based methods) بسمات3 word n-gram features and 8 character n-gram features، وتقنيات التعلم العميقCNN , RNN, Bi-RNN),GRU, Bi-GRU LSTM, and Bi-LSTM)، والأساليب القائمة على التعلم بالنقل Transfer Learning مثل (BERT and XLNet), فكانت أفضل النتائج باستخدام التعلم الآلي حيث كانت القيم كالتالي Micro)
Precision = 0.67, Micro Recall = 0.54, MicroF1 = 0.67).
B. الأعمال ذات الصلة باللغة العربية
قام الباحثون (Abdullah, et al., 2018) باقتراح نظام SEDAT لديه القدرة على تحديد وجود وشدة المشاعر. تمَّ الاعتماد على قاعدة بيانات مأخوذة من SemEval-2018 (Task 1: Affect in Tweets) للمهمتين El-reg, El-oc وكانت البيانات مقسمة لملف تدريب يحتوي على 1070 جملة وملف اختبار يحوي 730 جملة. تمَّ إجراء التجارب باستخدام خوارزميات التعلم العميقLSTM, CNN بمساعدة نماذج تضمين الكلمات وكانت قيمة مقياسPrediction تساوي 0.82. كما قام الباحثون (Baali & Ghneim, 2019) بتحليل المشاعر المأخوذة من التغريدات العربية باستخدام تقنيات التعلم العميق، واستخدم البحث قاعدة البيانات SemEval-2018 (Task 1: Affect in Tweets) للمهمة El-oc التي تتألف من 5600 تغريدة، وتحتوي على 1400 تغريدة لكل نوع من المشاعر التالية: الغضب، والخوف، والفرح، والحزن. وقد تم استخدام الشبكات العصبونية التلافيفية (CNN) وإنشاء نموذج word2vec باستخدام تطبيق Genism وتمت المقارنة بين أساليب التعلم التلقائي والتعلم العميق فحقق التعلم العميق نتائج أفضل
بالدقة Accuracy بقيمة تساوي 0.9982 وكانت قيمة مقياس F1 تساوي 0.9991. قام الباحثون (Almahdawi & Teahan, 2019) بإنشاء مجموعة بيانات عربية جديدة وفقاً لمشاعر Ekman الأساسية، تتكون مجموعة البيانات هذه من منشورات على فيسبوك مكتوبة باللهجة العراقية، وقاموا باستخدام تقنيات التعلم الآلي منهاZeroR, J48, Naive Bayes, Multinomial Naive Bayes, SVM, PPM, SMO. وقد كشفت الدراسة أن مصنف PPM يتفوق بشكل كبير على المصنفات الأخرى حيث حقق معدل F1 يساوي 0.61 ودقة Accuracy تساوي 86.9. حاول الباحثون (Chowdhury, et al., 2020) تعزيز مهمة تصنيف النص في مجموعة البيانات العربية باستخدام نموذج أحادي اللغة (سميQarib) مُدرَّب على اللغة العربية القياسية الحديثة MSA وغير الفصحى، تمَّ إجراء التدريب باستخدام خوارزميات التعلم التلقائي SVM ونماذج BERT وقد حققت نماذج BERT أفضل أداء حيث كانت قيمة F1 تساوي 0.81. قام الباحثون (Al-Twairesh, 2021) بالاعتماد على مدونات المهمة الأولى Affect In Tweets (AIT) في ورشة عمل SemEval-2018 (Saif, et al., 2018) للمهمتين El-reg, El-oc حيث أن البيانات عبارة عن مجموعة من التغريدات العربية التي تم تصنيفها لأربع مشاعر أساسية: الغضب، والحزن، والفرح، والخوف، اعتمدوا على مقارنة نتائج تطبيقTF-IDF وSVM مع مختلف نماذج التضمين (Word2Vec) وقاموا أيضاً بدراسة تأثير نماذج BERT فكانت أفضل النتائج باستخدام نموذج ArabicBert Large بمعدل F1 يساوي 0.77. وقام الباحثون (Abdul-Mageed, et al., 2021) باستخدام نماذج (ARBERT, MABERT, XLM-R) وأظهرت النتائج بوضوح أن MARBERT أقوى منARBERT، حيث حقق النموذج المقترح دقة Accuracy تساوي 0.77 بالاعتماد على قاعدة بيانات ضخمة مأخوذة من تغريدات Twitter. اقترح الباحثون (Alhuzali & Ananiadou, 2021) نموذج SpanEmo الذي يعتمد بشكل أساسي على نموذج BERT، اعتمد في اختباراته على قاعدة بيانات SemEval 2018 task1، بالتصنيف إلى 11 نوع من المشاعر. وبنتيجة الاختبارات فقد حقق النموذج المقترح باستخدام مقياس F1 قيمة 0.746 وذلك بالاعتماد على حساب تابع LCA وتابع BCE أثناء التدريب. اقترح الباحثون (Zhang, et al., 2022) مرمزاً متعدد الوسائط يشبه BERT لدمج تمثيلات الكلمات أطلق عليها TAILOR (versaTile multi-modAl learning for multI-labeL emOtion Recognition) أجرى الباحثون تجارب على مجموعة البيانات المعيارية CMU-MOSEI (Zadeh, et al., 2018) وقد حقق النموذج المقترح معدل F1 يساوي 0.56.
3. تهيئة قاعدة البيانات
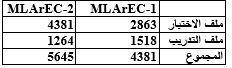
نظراً لندرة المدونات المكتوبة باللغة العربية الفصحى والمنمطة لعدة فئات من المشاعر، فقد بنيت المدونة المستخدمة في بحثنا هذا يدوياً على مرحلتين، حيث تمَّ الاعتماد على مدونات AIT في ورشة عمل SemEval-2018 . وهي تحوي عدة مدونات مكتوبة بعدة لغات وهي: (العربية، الإنكليزية، الإسبانية). تقسم كل مدونة من هذه المدونات إلى مدونات للتدريب والتطوير والاختبار. وقد تمَّ الاعتماد على ملفات المهمة Emotion Classification .(EC)في المرحلة الأولى تمَّ الاعتماد على المدونة التي تحوي جملاً عربية مكتوبة باللهجة العامية والمستخلصة من مجموعة من التغريدات على تويتر بمختلف اللهجات، ومصنفة إلى 11 فئة من فئات المشاعر (غضب، ترقب، اشمئزاز، خوف، فرح، حب، تفاؤل، تشاؤم، حزن، مفاجأة، ثقة). تمَّ دمج كل من ملفات التدريب والتطوير في ملف واحد من أجل التدريب. ثمَّ تمَّ تحويل جمل المدونة كاملة يدوياً إلى اللغة العربية الفصحى بعد إزالة كل الرموز التعبيرية من الجمل واستبدالها بكلمات توصف الرمز التعبيري سواء دلَّ على الفرح أو الحزن أو...، كما تمَّ أيضاً إزالة الهاشتاغ بتقسيمها إلى كلماتها الفعلية، فعلى سبيل المثال: يصبح الهاشتاغ #lovemusic كلمتين هما love music ومن ثمَّ ترجمتها إلى النص العربي المقابل بالفصحى. لم تتم إزالة كلمات الوقف لأهميتها في عملية تحديد الشعور. ومن ثمَّ تمَّ عرض جميع هذه الملفات على خبير لغوي من أجل تدقيق صحة صياغة الجمل وصحة تحويلها وصحة تنميطها. بلغ عدد الجمل الكلي في المرحلة الأولى4381 جملة للتدريب والاختبار. قمنا ببعض الإجراءات المسبقة لتسوية كلمات الجمل Normalization وذلك بحذف علامات التشكيل والهمزات وأحرف التطويل وإزالة الأقواس واستبدال التاء المربوطة بهاء والياء غير المنقوطة بياء. واستخدمنا لهذا الغرض مكتبة تاشفين (Tashaphyne). أما في المرحلة الثانية ومن أجل زيادة عدد الجمل فقد تمَّ الاعتماد على المدونة المكتوبة باللغة الإنكليزية وترجمة بعض الجمل يدوياً إلى اللغة العربية الفصحى، وقد بلغ عدد الجمل الكلي في هذه المرحلة 5645 جملة للتدريب والاختبار. يعرض (الجدول 1) عدد الجمل الموجودة في المدونتين (MLArEC-1, MLArEC-2) لكل من ملفات التدريب والاختبار، وقد جرى تقسيم العينات بنسبة 80:20 (80 تدريب و20 تطوير) أثناء التدريب.
الجدول 1 عدد جمل المدونة الأولى والمدونة الثانية
up
|
| |
المنهجية المقترحة
نقوم في هذا البحث بإنشاء نموذج يقوم بتحديد المشاعر في الجمل المكتوبة باللغة العربية الفصحى، والمصنفة إلى 11 فئة من المشاعر. تمَّ تطبيق ومقارنة منهجيات التعلم بالنقل (Transfer learning) على المدونات المبنية. تمَّ استخدام أكثر من نموذج من نماذج التضمين BERT للغة العربية وتمَّ ضبطه على مسائل تصنيف المشاعر، حيث قدَّمت هذه النماذج أداءً متطوراً لهذا النوع من المسائل. تقوم نماذج BERT على تحويل الكلمات إلى رموز عددية وتقنيع بعضها لدراسة ارتباط الكلمات بعضها ببعض، بغض النظر عن شكل الكلمة بالتالي هي نماذج تعتمد على تضمين كلمة ضمن سياق معين . بين كل طبقة transformer وأخرى يستخدم BERT تابع التنشيط GLUE من أجل تحسين عملية الأداء. قمنا باستخدام مجموعة من النماذج والتي تعتمد على نموذج BERT وهي: نموذج Arabic-BERT (Safaya, et al., 2020)، نموذج ARBERT (Abdul-Mageed, et al., 2021)، ونموذج MABERT (Abdul-Mageed, et al., 2021). من أجل تحسين عملية التصنيف قمنا بإضافة شبكة تغذية أمامية خطية (FFN) يتبعها طبقة Droput وطبقة خطية تمت إضافتها لغرض Regulationiaztion والتصنيف على التوالي. في شبكة التغذية الأمامية هذه يوجد مخرجان من طبقة BERT ويتم تمرير الخرج الثاني أو المسمى الخرج المجمع إلى طبقة Droput ويتم إعطاء الخرج التالي للطبقة الخطية علماً أن تابع التنشيط المستخدم في هذه الطبقة الخطية هو تابع Tanh وستكون أبعاد هذه الطبقة الخطية بعدد الفئات الموجودة في مسألتنا (11 فئة) لأن هذا هو العدد الإجمالي للفئات التي نتطلع إلى تصنيف نموذجنا فيها. وبالتالي فإن مخرجات الطبقة النهائية هي ما سيتم استخدامه لحساب قيم الخسارة الناتجة عن التصنيف الخاطئ ولتحديد دقة تنبؤ النماذج. تمَّت إضافة رؤوس تنبؤ إضافية إلى نموذج BERT من أجل كل شعور وتوسيع تنفيذ حزمة المحولات Transformers وبالتالي أصبح لدينا طبقة تجميع(pooling) وطبقة اتصال كاملة وطبقة إخراج (الشكل 1).
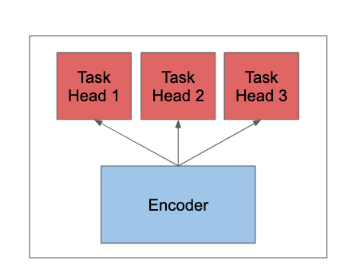
الشكل 1 نموذج لإضافة رؤوس تنبؤ لكل مهمة (شعور) على طبقة المرمز
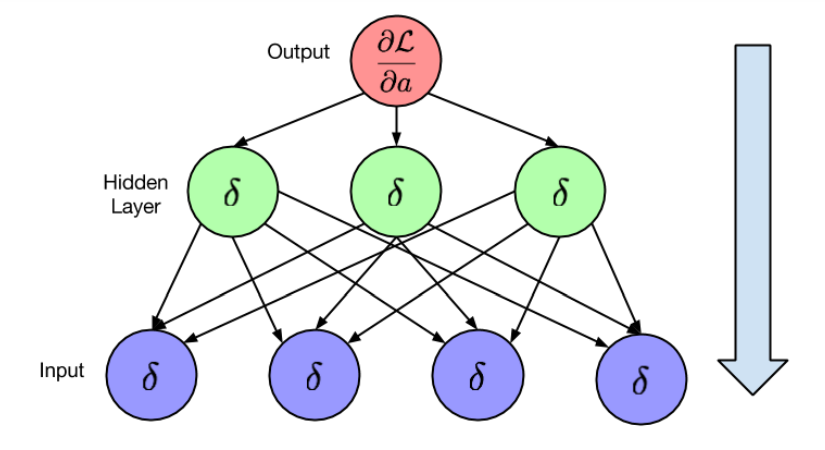
بما أنَّ المهمة المدروسة تخص مسائل التصنيف المتعدد الفئات فقد تمَّ استخدام تابع تنشيط من نوع sigmoid من أجل إعطاء القرار فيما إذا كانت تصنيف المشاعر صحيح أم لا، حيث تمَّ حساب مشتق دالة BCELoss مع تابع التنشيط Sigmoid من أجل كل فئة من فئات المشاعر في النموذج بطريقة Forward pass (الشكل 2) وبعدها قمنا بتحديث الأوزان من أجل كل عصر تدريب(Epoch) بطريقة Backward Pass (الشكل 3) ليتم حساب قيمة BCELoss في مرحلة التدريب.
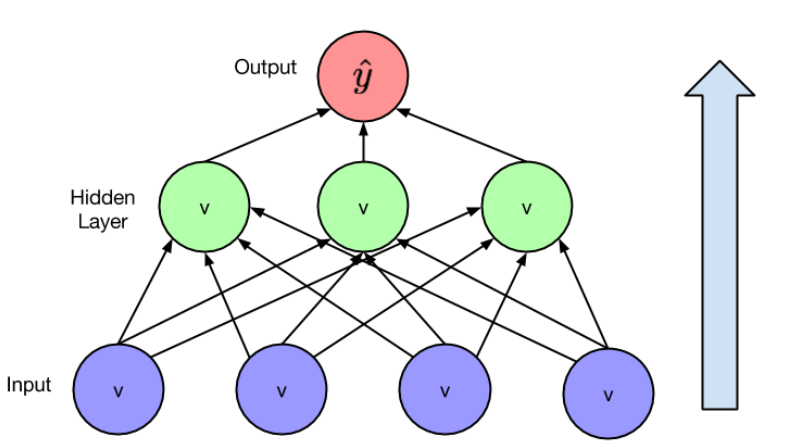 
الشكل 2 طريقة Forward Pass
الشكل 3 طريقة Backward Pass
انطلاقاً من أن لكل خرج لهذه الشبكة احتمال معين فقد عملنا على ضبط قيم العتبة وقياس كفاءتها تبعاً لمراحل التدريب لنحصل على أفضل دقة عند حساب Micro-F1، حيث جرى تعيين قيم عتبة القرار بناءً على ضبط قيم Macro-F1 وقيم Micro-F1, وقد لوحظ أن ضبط قيم العتبة بين 0.4 و 0.6 قد أدى إلى زيادة الأداء في مقياس Micro-F1، وأظهر ضبط قيم عتبة القرار نتيجة فعالة في التنبؤ بعدة فئات من المشاعر التي لها عدد جمل منخفض للغاية في المدونة المقترحة حيث أن ضبط هذه القيم قد أعطى نتيجة فعالة لأكثر من ثلث بيانات الاختبار. أجرينا جميع التجارب على Google Colab، بذاكرة 4 GB وحجم تخزين 39 GB، وباستخدام مكتبة التطوير pytorch. جرى استخدام أربعة مقاييس تقييم مختلفة وهي " Jaccard-Index , Micro-avg Precision, Micro-avg Recall , Micro-avg F1 Score". تمَّ ضبط حجم الدُفعة (Batch-Size) على 16,32,128 ومعدل التعلم على 2e-5 باستخدام مُحسِّن Adam، وتم تعيين loss parameter على BCEWithLogitsLoss، كما تمَّ تدريب النماذج على 10 عصور تدريب (Epochs) .
up
|
| |
تحليل النتائج
بعد عدة تجارب بالاعتماد على تغيير عصور التدريب (Epochs) بالتزامن مع تغيير نموذج التضمين وجدنا أنَّ أفضل النتائج تمَّ الحصول عليها من خلال استخدام عدد عصور تدريب(Epochs) يساوي 10 عصور مع حجم دفعة (Batch-Size) تساوي 32. تقدم الجداول أدناه نتائج مقاييس الأداء المذكورة أعلاه على قاعدتي البيانات"MLArEC-1" و "MLArEC-2". يقدِّم الجدول 2 مقارنة لأداء نماذج التضمين المستخدمة على المدونة الأولى MLArEC-1
الجدول 2 مقارنة أداء نماذج تضمين BERTBase, ARBERT, MABERT على المدونة MLArEc-1
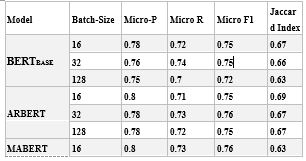

من النتائج السابقة التي أجريت على المدونة الأولىMLArEC-1، فإنَّ أفضل أداء تمَّ تحقيقه كان باستخدام MABERT بحجم دفعة 32 حيث كانت قيمة Micro-F1 تساوي 0.78 وقد حقق مقياس Jaccard Index معدل 0.69، أما باستخدام ARBERT فقد حاز المرتبة الثانية بمعدل Micro-F1 يساوي 0.76 مع معدل Jaccard Index بقيمة تساوي 0.67. ويرجح أن السبب المحتمل للحصول على نتائج منخفضة هو أن كمية البيانات المستخدمة في التدريب قليلة جداً، وعادةً ما تتطلب طرق التعلم قدراً كبيراً من البيانات للتدريب الجيد.
يقدِّم الجدول 3 مقارنة لأداء نماذج التضمين المستخدمة على المدونة الثانية MLArEc-2
الجدول 3 مقارنة أداء نماذج تضمين BERTBase, ARBERT, MABERT على المدونة MLArEc-2
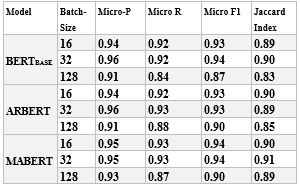
من النتائج السابقة التي أجريت على المدونة الثانيةMLArEC-2 ، فإنَّ أفضل أداء تمَّ تحقيقه كان باستخدام MABERT بحجم دفعة 32 بمعدل Micro-F1 يساوي 0.94 وقد حقق مقياس Jaccard Index معدل 0.91، أما باستخدام BERTBASE فقد حاز المرتبة ذاتها بمعدل Micro-F1 يساوي 0.94 لكن مع اختلاف طفيف بقيمة مقياس Jaccard Index حيث أشارت التجربة إلى قيمة تساوي 0.90 حيث أن مقياس Jaccard Index أعطى دليل واضح على مدى نسبة التشابه بين فئات المشاعر التي تم التنبؤ بها من أجل جمل الاختبار وبين فئات المشاعر الصحيحة التي تم تنميط الجمل بها، كما نلاحظ أن النموذج الآخر ARBERT قد أعطى نتائج متقاربة من النتائج التي تمَّ الحصول عليها باستخدام MABERT, BERTBASE.
يوضح الشكل 4 مقارنة نماذج التضمين BERTBase, ARBERT, MABERT من أجل المدونتين MLArEc-1, MLArEc-2 ولاحظنا وضوحاً أنَّ نتائج أداء النموذج باستخدام المدونة MLArEc-2 أفضل من نتائج أداء النموذج التي حصلنا عليها باستخدام المدونة MLArEc-1، وذلك بسبب كون المدونة MLArEc-2 أكبر من المدونة .MLArEc-1 وهذا يجعلنا نستنتج أنه بزيادة عدد البيانات أعطى النموذج أداء أفضل، أيضاً نلاحظ أنه وفق مقياس Micro-F1 فإن جميع النماذج تعطي نتائج جيدة باستخدام حجم دفعة تساوي 32 وتتحسن هذه النتائج بزيادة عدد بيانات التدريب واستخدام هذا الرقم الذي يمثل حجم الدفعة(Batch-size) يقلل من قيم الخطأ عند استخدام تابع BCE.
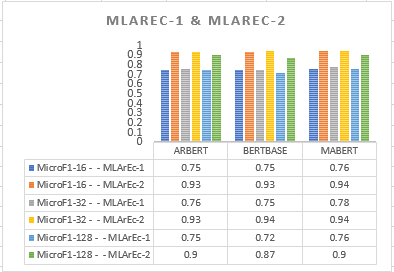
الشكل 4 مقارنة نماذج التضمين BERTBase, ARBERT, MABERT من أجل المدونة MLArEc-2 ,MLArEc-1
بالمقارنة مع نتائج البحث المشابه (Alhuzali & Ananiadou, 2021) تمَّ اختبار النموذج المقترح على مدونة مكتوبة باللغة العامية تحوي 4381 جملة وهي ذات المدونة التي تمَّ العمل على تحويل الجمل فيها إلى اللغة الفصحى لاختبار دقة النموذج مع اختلاف طبيعة النص وكانت النتائج باستخدام نموذج "asafaya/bert-base-arabic" وحجم دفعة (batch-size) يساوي 32 وعدد عصور تدريب (Epochs) يساوي 10 بمعدل Micro-F1 يساوي 0.76 نلاحظ أنَّ النموذج المقترح قد حقق نتائج أفضل مقارنة بالنموذج المقارن وباستخدام نموذج "UBC-NLP/ARBERT" وحجم دفعة (batch-size) يساوي 32 وعدد عصور تدريب (Epochs) يساوي 10 بمعدل Micro-F1 يساوي 0.75 وباستخدام نموذج "UBC-NLP/MARBERT" وحجم دفعة (batch-size) يساوي 32 وعدد عصور تدريب (Epochs) يساوي 10 بمعدل Micro-F1 يساوي 0.74. نلاحظ أنه من النتائج السابقة على المدونة المكتوبة باللهجة العامية أنَّ أفضل أداء تمَّ تحقيقه باستخدام
خلاصة التجربة: يشير هذا الأداء إلى أن نماذج التعلم القائمة على BERT يمكن أن تعطِ نتائج جيدة نسبياً في تصنيف المشاعر متعددة الفئات عندما تكون بيانات التدريب صغيرة مقارنة بأساليب التعلم العميق، ولكنها تعطي أداء أفضل بزيادة عدد البيانات. ولا يجب أن ننسى أن لكل نموذج من النماذج القائمة على BERT بنية تصميمية تختلف عن النماذج الأخرى من نفس الفئة، وذلك بسبب اختلاف حجم البيانات، وطبيعة اللغة، وحجم المفردات، وعدد خطوات التدريب، وما إلى ذلك. لذلك نلاحظ تفاوت الأداء باستخدام كل نموذج على حده.
|
| |
الخاتمة
عرضنا في هذا البحث مجموعة المعطيات التي قمنا بإنشائها بهدف تحديد المشاعر باللغة العربية الفصحى، وتصنيف الجمل العربية باستخدام التعلم بالنقل. جرت المقارنة بين نتائج عدد من النماذج المدربة مسبقاً الخاصة باللغة العربية والقائمة على نموذجBERT. بينت المقارنة على معطيات الاختبار وهي جمل تحوي أكثر من فئة من المشاعر (11 فئة) أن نموذج MABERT قد أعطى أفضل قيم F1 بنسبة 0.94، وتكمن فائدة هذا النموذج في أن بناءه لا يحتاج إلى مدونة ضخمة للتدريب. نسعى مستقبلاً لتوسعة مجموعة المعطيات المنمطة التي نعمل عليها ودراسة تأثير التوسع على النتائج بشكل أفضل، كما يمكن أن نطور البحث لاستخدام نماذج أخرى تخدم غرض البحث عن طريق استخدام أساليب أخرى من أساليب التعلم بالنقل، أيضاً يمكن توسيع نطاق البحث ليشمل مستوى نص مكتوب باللغة العربية الفصحى عوضاً عن العمل على مستوى الجملة.
up
|
| |
Reference
Abdullah, M., Hadzikadicy, M. & Shaikhz, S., 2018. SEDAT: Sentiment and Emotion Detection in Arabic Text using CNN-LSTM Deep Learning. In: 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA). s.l.:s.n., pp. 835-840.
Abdul-Mageed, M., Elmadany, A. & Nagoudi, E. M. B., 2021. ARBERT & MARBERT: Deep Bidirectional Transformers for Arabic. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). s.l.:Association for Computational Linguistics, pp. 7088--7105.
Abdul-Mageed, M., Elmadany, A. & Nagoudi, E. M. B., 2021. ARBERT and MARBERT: deep bidirectional transformers for Arabic. arXiv preprint arXiv:2101.01785. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). s.l.:Association for Computational Linguistics, pp. 7088--7105.
Adam, P. et al., 2017. Automatic differentiation in pytorch. s.l., s.n.
Alhuzali, H. & Ananiadou, S., 2021. SpanEmo: Casting Multi-label Emotion Classification as Span-prediction. In: In Proceedings of the 16th conference of the European Chapter of the Association for Computational Linguistics (EACL-2021). s.l.:s.n.
Almahdawi, A. J. & Teahan, W. J., 2019. A New Arabic Dataset for Emotion Recognition. s.l., Springer, Cham, pp. 200-216.
Al-Twairesh, N., 2021. The Evolution of Language Models Applied to Emotion Analysis of Arabic Tweets. Information, pp. 2078-2489.
Baali, M. & Ghneim, N., 2019. Emotion analysis of Arabic tweets using deep learning approach. Journal of Big Data, pp. 2196-1115.
Chowdhury, A. S. et al., 2020. Improving Arabic Text Categorization Using Transformer Training Diversification. In: Proceedings of the Fifth Arabic Natural Language Processing Workshop. s.l.:Association for Computational Linguistics, p. 226–236.
Iqra, A., Grigori, S., Helena, G.-A. & Rao Muhammad Adeel, N., 2022. Multi-Label Emotion Classification on Code-Mixed Text: Data and Methods. IEEE Access, pp. 8779-8789.
Iqra, A., Noman, A., Grigori, S. & ́omez, A. H. G., 2020. Multi-label Emotion Classification using Content-Based Features in Twitter. Computación y Sistemas, p. 1159–1164.
Jabreel, M. & Moreno, A., 2019. A Deep Learning-Based Approach for Multi-Label Emotion Classification in Tweets. Applied Science.
Safaya, A., Abdullatif, M. & Yuret, D., 2020. KUISAIL at SemEval-2020 Task 12: BERT-CNN for Offensive Speech Identification in Social Media. In: Proceedings of the Fourteenth Workshop on Semantic Evaluation. s.l.:International Committee for Computational Linguistics, pp. 10.18653/v1/2020.semeval-1.271.
Saif, M., Felipe, B.-M., Mohammad, S. & Svetlana, K., 2018. Semeval2018 task 1: Affect in tweets. s.l., n Proceedings of the International Workshop on Semantic Evaluation (SemEval-2018), pp. 1-17.
Ying, W., Xiang, R. & Lu, Q., 2019. Improving Multi-label Emotion Classification by Integrating both General and Domain Knowledge. e 2019 EMNLP Workshop W-NUT: The 5th Workshop on Noisy User-generated Text, p. 316–321.
Zadeh, A. B. et al., 2018. Multimodal Language Analysis in the Wild: {CMU}-{MOSEI} Dataset and Interpretable Dynamic Fusion Graph. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). s.l.:Association for Computational Linguistics, pp. 2236--2246.
Zhang, Y., Chen, M., Shen, J. & Wang, C., 2022. Tailor Versatile Multi-modal Learning for Multi-label Emotion Recognition. arXiv preprint arXiv:2201.05834.
up
|
| |
|
|




