|
|
|
| |
اسامه إبراهيم
صلاح الدوه جي
سهيل الحمود
|
| |
الملخص
إن النمو السريع لانتشار أجهزة إنترنت الأشياء أصبح يحدث فارقاً كبيراً في حياتنا اليومية، ويساعدنا على اتخاذ قرارات حاسمة في كثيرٍ من قطاعات الحياة. حقيقةً إن طبيعة هذه البيئة تفرض اعتباراتٍ معينة، فعلى عكس الشبكات في الماضي فقد كانت مكونة من عدد صغير من آلات الأغراض العامة، فإن شبكات إنترنت الأشياء تتكون بشكل متزايد من عدد كبير من الأجهزة المتخصصة المصممة للقيام بمهمة واحدة، ومما لا يمكن تجاهله أن المهمة المتخصصة والطبيعة المقيدة لهذه الأجهزة في كثير من الأحيان يجعل من الصعب تأمينها، ولكن من السهل تحليلها خارجياً، وهنا لا يمكننا إغفال مسألة الموارد الحسابية والتخزينية المحدودة في أنظمة إنترنت الأشياء، والتي تضع قيوداً على تثبيت برامج الأمن التقليدية؛ لذلك فإن الأنظمة التقليدية للكشف عن التسلل (IDS) أصبحت غير فعّالة في هذه البيئة؛ بسبب طبيعتها غير المتجانسة، والازدياد التدريجي لنقاط الضعف؛ لذلك كان لابد من إعادة دراسة هذا المجال ضمن قيود هذه البيئة، كون موارد المعالجة المحدودة لا تسمح باستخدام آليات الأمان القياسية على العقد، وتقديم منهجيات تراعي هذه القيود وتحل هذه المسألة ضمن سياق البيانات الضخمة. نقدّم في هذه الدراسة الاستقصائية مراجعة حول مختلف التقنيات والمنهجيات المستخدمة في اكتشاف البيانات الشاذة في تدفقات البيانات الضخمة بشكل عام وتدفقات انترنت الأشياء بشكل خاص بالاعتماد على طرائق التعلّم الآلي مع دراسة مُقارنة لتحديد الخوارزمية الأفضل للعمل على تطويرها لاحقاً لتكون مناسبة للعمل في بيئات الشبكات محدودة الموارد، وبناء نموذج مفاهيمي لاكتشاف الشذوذ في بيئة انترنت الأشياء معتمد على الخوارزمية الأفضل ضمن سياق هذه البيئة ومفهوم البيانات الوصفية، والخوارزميات وبنى المعطيات الاحتمالية. بنتيجة الدراسة المقارنة وجدنا أن خوارزمية الغابة العشوائية Random Forest هي الخوارزمية الأفضل في بيئات البيانات الضخمة بشكل عام، وبيئة انترنت الأشياء بشكل خاص، وقدمنا مقاربة اكتشاف هجينة متطورة ذاتياً وديناميكية من حيث دقة الكشف.
|
| |
up |
| |
Abstract
The rapid growth of Internet of Things (IoT) devices is making a huge difference in our daily lives and helps us make critical decisions in many sectors of life. Indeed, the nature of this environment dictates certain considerations. Unlike networks in the past that were made up of a small number of general-purpose machines, IoT networks are increasingly made up of a large number of specialized devices designed to do a single task. The Specialized task and Constrained nature of these devices often makes them difficult to secure, but it is easy to analyze them externally, and here we cannot overlook the issue of limited computational and storage resources in IoT systems, which place restrictions on the installation of traditional security software; Therefore, traditional intrusion detection systems (IDS) have become ineffective in this environment; Because of its heterogeneous nature and the gradual increase in vulnerabilities, so it was necessary to re-study this field within the constraints of this environment, Because of limited processing resources which do not allow the use of standard security mechanisms on nodes, and provide methodologies that take into account these limitations and solve this issue within the context of big data. In this survey, we present a review of the various techniques and methodologies used in Detecting anomalies in Big Data streams in general and Internet of Things streams in particular, based on machine learning methods with a comparative study to determine the best algorithm to work on to develop it later to be suitable for working in Constrained networks environments Resources, and building a conceptual model for anomaly detection in the Internet of Things environment based on the best algorithm within the context of this environment and the concept of Metadata, probabilistic data structures and algorithms. As a result of the comparative study, we found that the Random Forest algorithm is the best algorithm in the big data environments in general, and the Internet of Things environment in particular, and we presented a self- evolving and dynamic hybrid detection approach in terms of detection accuracy
|
| |
up |
| |
المقدمة
في السنوات الأخيرة، بدأ عصر البيانات الضخمة فارضاً ثورة التكنولوجيا الجديدة على العالم، ولكن البيانات الضخمة أمست معضلةً تعجز أمامها التقنيات الحالية من حيث الدّقة والأداء [23]، ولاسيما بيئات الشبكات الخاصة ذات الموارد المحدودة مثل بيئة انترنت الأشياءIoT وشبكات الحساسات اللاسلكيةWSN وشبكات المحمول المخصصةMANETs وغيرها [21].
تعتبر عملية اكتشاف البيانات الشاذة واحدة من أهم العمليات في كافة المجالات العلمية والتطبيقية وتستخدم على نطاق واسع في التطبيقات مثل اكتشاف الاختراقات في تطبيقات أمن الشبكات واكتشاف معاملات بطاقات الائتمان الاحتيالية أو مطالبات التأمين أو تقارير النفقات أو المعلومات المالية وغيرها من التطبيقات الطبية[23] .
لقد تمّت دراسة البيانات الشاذة منذ زمن بعيد وقد ظهرت العديد من التقنيات المتنوعة التي تناسب تطبيقات محدَّدة أو تلك التي يمكن وصفها بالتقنيات العامة. في وقتنا الحالي أصبحت هذه المشكلة أكثر صعوبة في عصر البيانات الضخمة؛ بسبب التزايد الأسي في حجم البيانات وتنوعها وسرعة توليدها وتغيرها؛ مما أدى لظهور حالات شاذة أكثر تعقيداً من ذي قبل، فلو تطرّقنا لتلك الأسباب وأسقطناها على طبيعة التطبيق؛ لنثبت ارتباطها الوثيق بمسألة البيانات الضخمة، وتناولنا مسألة اكتشاف الاختراقات في حركة مرور الشبكة على سبيل المثال، فأننا نجد أن السببين الأهم يتلخصان بنقطتين وهما:
1. إن التقنيات والأساليب الحالية للكشف عن النقاط الشاذة ليست فعَّالة بما فيه الكفاية؛ لأن الطرق المستخدمة في تنفيذ الهجمات أصبحت أكثر تعقيداً وأكثر تشابهاً مع حركة المرور العادية؛ لذلك تمَّ سابقاً اقتراح تقنيات مختلفة لتمييز حركة المرور العادية عن تلك القادمة من الاختراقات باستخدام تقنيات التعلم الآلي [1].
2. إن تزايد استخدام الخدمة القائمة على الإنترنت جعل حجم حركة مرور الشبكة كبيراً ومعقداً؛ لذك فقد تواجه أدوات المعالجة التقليدية صعوبات في التعامل مع هذه البيانات الضخمة والمعقدة، وهنا برزت الحاجة الملحة لإيجاد خوارزميات يمكنها تصنيف حركة مرور الشبكة بدقة وفي الوقت نفسه تستغرق زمناً أقل للتصنيف و التنبؤ [2].
|
| |
up |
| |
منهجية الدراسة
لقد تمَّ دراسة وتقييم الأداء العام لخوارزميات التعلّم الآلي من حيث دقة الكشف وزمن البناء وزمن التنبؤ ومعايير أخرى، حيث تمّ استخدام أدوات معالجة البيانات الضخمة لاكتشاف الشذوذ في حركة مرور الشبكة؛ بسبب الاستخدام المتزايد للخدمة القائمة على الإنترنت، وحجم حركة مرور الشبكة الذي أصبح كبيراً ومعقداً؛ مما جعل أدوات المعالجة التقليدية تواجه صعوبات في التعامل مع هذه البيانات الكبيرة والمعقدة. سنقوم في هذه الدراسة باستعراض تقنيات اكتشاف البيانات الشاذة في تدفقات البيانات الضخمة باستخدام تقنيات وطرائق التعلّم الآلي وفقاً لطبيعة المسألة التي تحاول التقنية حلّها، وبعد استعراض التقنيات المختلفة سيتم إجراء دراسة مقارنة بين هذه التقنيات وفق النموذج التالي:
1. ما هي أداة البيانات الضخمة المستخدمة لمعالجة مجموعة البيانات المُختارة إن وجدت؟
2. ما هي مجموعة الخوارزميات المستخدمة لتحقيق أسلوب اكتشاف الشذوذ المقترح؟
3. ما هي بيئة البحث ومجموعة البيانات التي تمّ الاعتماد عليها في عملية التحقيق أو المقارنة؟
4. ما هي الخوارزمية الأفضل عند استخدام العديد من الخوارزميات في العمل؟
ثم سنجيب على أهم الأسئلة البحثية التي أثرناها وهي:
1. ما هي خوارزمية التعلّم الآلي الأفضل من حيث زمن التصنيف، وزمن التنبؤ، والدقة والاستدعاء والخصوصية في سياق البيانات الضخمة ؟
2. ما هي الخوارزميات الأخرى التي قد تعمل بشكل جيد في سياق البيانات الضخمة؟
3. ما هي خوارزمية التعلّم الآلي الأفضل في بيئة انترنت الأشياء ؟
4. ما هي الخوارزميات الأخرى التي قد تعمل بشكل جيد في بيئة انترنت الأشياء؟
لقد قمنا بتلخيص أهم الدراسات السابقة بالجدول(1):
|
Best Algorithms
|
Dataset/ Environment
|
Algorithm used
|
Big Data tool
|
Related work /Date
|
|
Random Forest, decision tree
|
HAI/ SCADA
|
K-Nearest Neighbors (K-NN), Decision Tree (DT), Random Forest (RF)
|
/
|
[6] / 2021
|
|
DNN, Naïve Bayes
|
Synchrophasor /Big Data
|
Deep Neural Networks, Support Vector Machines (SVM), Naïve Bayes, Decision Trees, Random Forest
|
Apache Spark
|
[9] / 2017
|
|
Random Tree
|
UNSW‑NB 15
/Big Data
|
Naïve Bayes, REP TREE, Random Tree, Random Forest, Random Committee, Bagging and Randomizable Filtered
|
Apache Spark
|
[10] / 2018
|
|
Random Forest
|
UNSW‑NB 15
/Big Data
|
SVM, Naïve Bayes, Decision Tree and Random Forest
|
Apache Spark
|
/ 2018 [12]
|
|
Random Forest
|
NSL-KDD Cup 99, KDD Cup 99/Big Data
|
Logistics Regression, Random Forest, Naïve Bayes and Gradient Boosted Trees
|
Apache Spark
|
[2] / 2018
|
|
Random Forest
|
KDD Cup 99 /Network
|
Modified K-means, SVM, J.48, Naïve Bayes, Decision Table, Principle Component Analysis (PCA)-Linear Discriminant Analysis (LDA)-SVM, Logistics Regression (LR), Decision Tree, Artificial Neural Network (ANN), LDA, Classification and Regression Tree (CART), Random Forest
|
/
|
[13] / 2020
|
|
Random Forest
|
CICIDS-2017, UNSW-NB15, ICS / Networks
|
Logistic Regression, Gaussian Naive Bayes (GNB), K-NN, Decision Tree, Adaptive Boosting (AdaB), Random Forest, Convolutional Neural Network (CNN), CNN- Long Short-Term Memory (LSTM), LSTM, Gated Recurrent Units (GRU), Recurrent Neural Network (RNN), Deep Neural Network (DNN)
|
/
|
[14] / 2020
|
|
Random Forest
|
Real Traffic Data/ IoT (Smart Home Network)
|
Random Forest, Decision Tree, SVM, ANN, Gaussian Naive Bayes, K-Nearest Neighbours
|
/
|
[15] / 2019
|
|
Random Forest
|
Real Traffic data/ IoT
|
RF, Decision Tree, SVM, Logistic Regression
|
/
|
[16] / 2019
|
|
Random Forest
|
Virtual Traffic data/ IoT
|
Logistic Regression, RF, Decision Tree, ANN
|
/
|
[17] / 2019
|
|
Random Forest
|
Real Traffic data/ IoT
|
Naïve Bayes, Random Forest, K-Nearest Neighbours
|
/
|
[18] / 2019
|
|
Random Forest, ANN
|
Different Datasets conditions / IoT
|
SVM, K-NN, Random Forest, Decision Tree, ANN
|
/
|
[19] / 2019
|
|
Random Forest
|
IoT-23/ IoT
|
Naïve Bayes, Random Forest, Multi-Layer Perceptron, SVM, AdaBoost
|
/
|
[20] / 2021
|
مقارنة وتحليل:
قدمنا في الفقرة السابقة عرضاً لمجموعة من الأعمال البحثية التي قارنت من حيث الأداء بين خوارزميات التعلّم الآلي وفقاً لنموذج المقارنة المعرّف سابقاً، وسنقوم فيما يلي بإجراء دراسة مقارنة وتحليل لأهم الأعمال، وسوف نجيب عن الأسئلة المثارة سابقاً.
1. ما هي خوارزمية التعلّم الآلي الأفضل من حيث زمن التصنيف، وزمن التنبؤ، والدقة والاستدعاء والخصوصية في سياق البيانات الضخمة؟
إن النتائج المقدّمة في [6] و [12] و [2] و [13] و[14] أتفقت على حقيقة تجريبية مفادها أن خوارزمية الغابة العشوائية Random Forest تتمتع بأفضل أداء في اكتشاف الحالات الشاذة في سياق البيانات الضخمة ضمن مجموعات بيانات مختلفة، ولكن ذلك لا ينفي وجود آراء مختلفة، حيث أظهرت نتائج المقارنة في [10] أن Random Tree هي الأفضل بناءً على معايير الأداء المختلفة، أما في [9] فوجد أن الشبكة العصبية العميقة DNN تعطي أعلى دقة لمجموعة البيانات الخامة، وعند تطبيق تقنية PCA على مجموعة البيانات كانت Naïve Bayes هي الأفضل من حيث الدقة، أما عند المقارنة من حيث معدل الخطأ، فأعطت كل من DNN و Naïve Bayes المعدّلات الأقل، ففي هذين العملين دخلت خوارزمية الغابة العشوائية Random Forest ضمن التقييم ولكنّها لم تكن الأفضل.
2. ما هي الخوارزميات الأخرى التي قد تعمل بشكل جيد في سياق البيانات الضخمة ؟
استخدم [5] و [7] خوارزمية التجميع K-means وقد أثبتت النتائج التجريبية فعاليتها في بيئة البيانات الضخمة، في حين ركّزت الأعمال [3] و [4] و [8] و [11] على استخدام خوارزمية SVM، وعندما تمّ إجراء مقارنة بين SVM و K-NN من حيث الصحة accuracy في [11] كانت SVM هي الأفضل من أجل مجموعة كبيرة من الميزات، وفي حين تفوقت K-NN بقليل من أجل مجموعة أقل من الميزات.
3. ما هي خوارزمية التعلّم الآلي الأفضل في بيئة انترنت الأشياء ؟
أجريت المقارنة في [15] و[16] و[18] بين مجموعات مختلفة من خوارزميات التعلّم الآلي ضمن سياق مجموعات بيانات جُمعت في بيئة حقيقية لانترنت الأشياء، بينما استخدم [17] و [19] معايير مختلفة وضمن مجموعات بيانات جُمعت في بيئة افتراضية لانترنت الأشياء، وعلى النقيض من ذلك اعتمد [20] على مجموعة البيانات الحديثة IoT-23 والتي تقدّم مجموعة بيانات كبيرة من الإصابات الحقيقية والمُصنَّفة للبرامج الضارة لإنترنت الأشياء وحركة مرور إنترنت الأشياء الحميدة للباحثين بهدف تطوير خوارزميات التعلم الآلي، وقد أتفقت جميع هذه الدراسات على حقيقة تجريبية مفادها أن خوارزمية الغابة العشوائية Random Forest تتمتع بأفضل أداء في اكتشاف الحالات الشاذة في سياق بيئة انترنت الأشياء، وذلك يقودنا إلى أن خوارزمية الغابة العشوائية هي المرشّح الأفضل لنجري عليها عملية التحسين ولتعتمد عليها المقاربة لاحقاً.
4. ما هي الخوارزميات الأخرى التي قد تعمل بشكل جيد في بيئة انترنت الأشياء؟
إن [17] وجد أن خوارزمية الشبكة العصبية الاصطناعية ANN أعطت الدقة نفسها، التي تعطيها خوارزمية الغابة العشوائية(RF)، ولكن المقاييس الأخرى أثبتت أن خوارزمية Random Forest تعمل بشكل أفضل نسبياً، أما [19] فقد وجد أن ANN توفر أفضل درجات الصحة accuracy بنسبة 99٪ أثناء تحليل حركة مرور إنترنت الأشياء الضارة إلى جانب Random Forest، وكذلك [22] اعتمد على ANN لبناء نظام لاكتشاف هجمات DDoS في بيئة انترنت الأشياء قائم على التعلّم الآلي، وقد أثبت النظام المقترح فعاليته في الكشف عن هجمات DDoS في بيئة IoT، ومما سبق نجد أن ANN قد تعمل بشكل جيد في بيئة انترنت الأشياء.
النموذج المفاهيمي:
إن التوجهات الحديثة في السنوات الأخيرة تفرض على أي منهجية جديدة لاكتشاف البيانات الشاذة أن تراعي قيود البيانات الضخمة، وبالتالي تدعم إمكانية توظيفها لاكتشاف الشذوذ في هذه البيئات، وتعدُّ البيانات الوصفية Metadata من العوامل التي تغير قواعد اللعبة في عالم البيانات الضخمة؛ لأنها يمكن أن تمنحنا ميزة تنافسية، فكلما استخدمنا قوة البيانات الضخمة بشكل أفضل لتوجيه قرارات العمل زاد نجاح العمل، وكلَّما زادت قوة البيانات الوصفية الخاصة بنا، زادت السرعة في استخراج المعلومات القابلة للتنفيذ واتخاذ قرارات أفضل وأسرع؛ لذلك فإنها تعدُّ ضرورية لكفاءة أنظمة المعلومات وخاصة في مسألة تصنيف البيانات [24]. حقيقةً إن كلية الحقوق في جامعة هارفارد تعرّف البيانات الوصفية Metadata بأنها البصمة إلكترونية fingerprint التي تضيف تلقائياً سماتاً تعريفية [25]؛ وبناءاً على ما سبق فإننا سوف نقترح استخدام هذا المفهوم لاستخراج البصمة الألكترونية للهجمات المعروفة، ولاحقاً سوف نستخدم هذه البصمات لبناء نهج قائم على التوقيع signature-based approach، ولكن هذا النوع من النُّهج يعاني من مشكلة أساسية لابد من حلّها وهي أنه مع نمو حجم قاعدة بيانات التوقيع، فإن مقارنة المدخلات بقاعدة بيانات كبيرة سوف تصبح مكلفة من الناحية الحسابية؛ لذلك نقترح حلّاً جديداً لهذه المشكلة ألا وهو الخوارزميات وبنى المعطيات الاحتمالية PDSA؛ والسبب الرئيسي لاستخدامها كونها توفر زمن ثابت للاستعلام، وتعرّف البنى الاحتمالية بأنها هياكل البيانات التي تعتمد على تقنيات التجزئة المختلفة، وتتميز عن بنى البيانات الحتمية أنها تعطي إجابات تقريبية، ولكن بطرق موثوقة لتقدير الأخطاء المحتملة [26]، ولكن السؤال الأهم ماذا تقدّم لنا بالمقابل؟ ويعود السبب في اختيارها إلى كونها تعوّض عن الإجابة التقريبية من خلال ثلاثة عوامل باتت حاجة ملحة بظل توجه العالم نحو البيانات الضخمة وهي:
1) متطلبات الذاكرة المنخفضة للغاية عندما نستخدم هذه التقنية الرياضية.
2) توفر زمن ثابت للاستعلام.
3) توفر قابلية التوسع Scaling [26].
تقوم فكرتنا الأساسية على دمج النهج المقترح والقائم على التوقيع مع نهج قائم على الشذوذ ومعتمد على خوارزمية RF بعد تطويرها كونها الأفضل بين خوارزميات التعلّم الآلي في بيئات البيانات الضخمة بشكل عام، وبيئة انترنت الأشياء بشكل خاص كما وجدنا سابقاً؛ بهدف إنشاء مقاربة اكتشاف هجينة متطورة ذاتياً، وعلى الرغم من كون تحقيق مثل هذه المقاربة سيكون معقداً، ولكنّها ستحل مشكلة النُّهج القائمة على التوقيع والمتمثلة بعدم قدرتها على اكتشاف هجمات اليوم الصفري zero-day attack أو الهجمات غير المعروفة؛ بسبب اعتمادها على تواقيع الهجوم المعروفة سابقاً، وهذا ما تعتبر النُّهج القائمة على الشذوذ جيدة فيه [22]، ومما لا يجب إغفال ذكره أن النظم القائمة على التوقيع تعطي معدلات كشف أعلى من النظم القائمة على الشذوذ في حالة هجمات الشبكة المعروفة [4]، وبالتالي ستقوم المقاربة المقترحة على مرحلتين:
1- مرحلة الاكتشاف: يتم في هذه المرحلة اكتشاف حركة المرور الضارة التي تنشأ من أجهزة إنترنت الأشياء بالاعتماد على نهج قائم على التوقيع ومعتمد على حل مسألة التشابه Similarity Problem، ولنلخص هذه المرحلة في عدّة خطوات:
A. نوجد بصمة البيانات(تابع الهاش) للبيانات الوصفية للحالة الشاذة(الهجوم في حالتنا).
B. نخزن البصمات في خزان للبصمات Fingerprints Store.
C. نحدد عتبة التشابه ثم نختبر دقة الكشف ونجري عملية الضبط.
D. تقوم خوارزمية التشابه بالكشف التلقائي والبحث عن مجموعات البيانات المماثلة لها أو المشابهة في خزان البصمات الخاص بنا، وهذا يجعل المهمة أقل صعوبة وأكثر كفاءة، وهنا سوف نستفيد من البنى والخوارزميات الاحتمالية المتخصصة بحل مشكلة التشابه Similarity Problem مثل:Locality Sensitive Hashing و MinHash و SimHash.
2- مرحلة تطوير المقاربة: يتم في هذه المرحلة استخدام النهج القائم على الشذوذ والمتمثل بالنسخة المطورة من خوارزمية الغابات العشوائية ERF لاكتشاف هجمات يوم الصفر والهجمات غير المعروفة وتخزن في مخزن الشذوذ ليعاد أخذ بصمتها وإضافتها لاحقاً لخزان البصمات.
يبين الشكل (1) أدناها المخطط الكتلي العام لهذه المقاربة الهجينة:
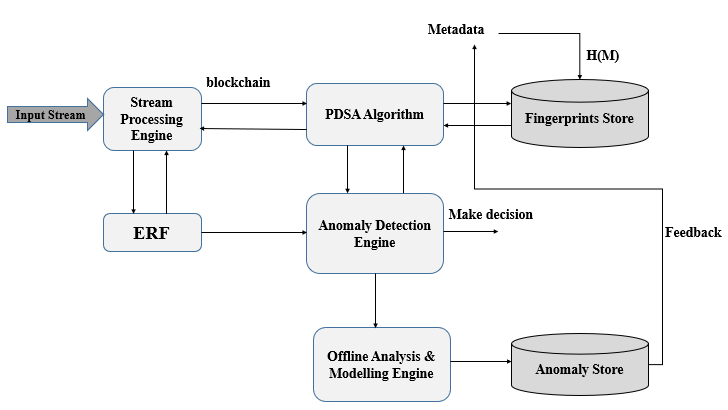
الشكل (1)
لقد تمَّ تصميم المقاربة الموضحة بالشكل (1) لتكون ذاتية التطور حيث يقتصر دور المرحلة الثانية القائم على خوارزمية الغابة العشوائية المطورةERF على اكتشاف الهجمات غير المعروفة وهجمات اليوم الصفري، ثم تحديث مخزن بصمات الهجمات، وعلى الرغم من أن تحقيق مثل هذه المقاربة يعتبر معقداً، لكنه سيحل مشكلتين أساسيتين من مشاكل النهج القائمة على التوقيع signature-based approach وهما:
1- المشكلة الأولى: هي أنه مع نمو حجم قاعدة بيانات التوقيع، فإن مقارنة المدخلات بقاعدة بيانات كبيرة سوف تصبح مكلفة من الناحية الحسابية؛ لذلك اقترحنا حلّاً جديداً لهذه المشكلة ألا وهو الخوارزميات وبنى المعطيات الاحتمالية PDSA؛ والسبب الرئيسي لاستخدامها كونها توفر زمن ثابت للاستعلام.
2- المشكلة الثانية: عدم قدرة هذا النوع من النُّهج على اكتشاف هجمات اليوم الصفري zero-day attack أو الهجمات غير المعروفة؛ بسبب اعتمادها على تواقيع الهجوم المعروفة سابقاً، وقد اقترحنا في المرحلة الثانية استخدام نسخة مطوّرة من خوارزمية الغابة العشوائية لحل هذه المشكلة كون النُّهج القائمة على الشذوذ قادرة على اكتشاف هجمات اليوم الصفري والهجمات غير المعروفة، ويقتصر دور المرحلة الثانية على تحديث قاعدة بيانات التوقيع دون الاعتماد التام في الاكتشاف على هذه المرحلة؛ والسبب يعود للتعقيد عند استخدام خوارزمية الغابة العشوائية حيث تتطلب المزيد من القوة والموارد الحسابية، وتستهلك فترة تدريب طويلة، وقد تم اختيار هذه الخوارزمية كونها كانت خوارزمية التعلّم الآلي الأفضل بناءاً على الدراسة والمقارنة النقدية التي قمنا بإجرائها.
نتوقع من المقاربة المذكورة أعلاه أن تحقق دقة عالية في اكتشاف الشذوذ؛ بسبب حلّها لأهم مشكلتين في النُّهج القائمة على التوقيع، فضلاً عن كون النُّهج القائمة على التوقيع تعطي معدلات كشف أعلى من النُّهج القائمة على الشذوذ في حالة هجمات الشبكة المعروفة؛ لذلك قررنا أن تلعب المرحلة الأولى الدور الأساسي في المقاربة، ومما لا يجب إغفال ذكره أن هذه المقاربة ديناميكية من ناحية دقة الكشف، حيث يمكن إجراء عملية ضبط للدقة؛ لأن بنى البيانات الاحتمالية تتميز بأنها تعطي إجابات تقريبية، ولكن بطرق موثوقة لتقدير الأخطاء المحتملة، ولكنّها بالمقابل ستعوضنا عن ذلك بمتطلبات منخفضة للذاكرة وزمن ثابت للاستعلام. لن نكتفي في عملنا بهذا البرهان النظري والحجج المنطقية التي تمَّ ذكرها سابقاً، وإنما سنعمل مستقبلاً على تحقيق هذا النموذج وإجراء اختبار عملي لدقة الشذوذ، وأيضاً سنجري عملية ضبط ومعايرة للدقة مقارنة مع زمن الاستعلام المستهلك.
|
| |
كلمات مفتاحية:
اكتشاف البيانات الشاذة، البيانات الضخمة، انترنت الأشياء، الشبكات محدودة الموارد، البيانات الوصفية، الخوارزميات وبنى المعطيات الاحتمالية.
key words
Detecting Anomalies, Big Data, Internet of Things, Resource Constrained Networks, Metadata, Probabilistic Data Structures and Algorithms
|
| |
up |
| |
خاتمة
قدمنا في هذا العمل دراسة ومقارنة نقدية حديثة لمنهجيات اكتشاف الشذوذ المعتمدة على طرائق التعلّم الآلي، وتوصلنا بعدها لاختيار خوارزمية التعلّم الآلي الأفضل في بيئة البيانات الضخمة بشكل عام، وبيئة انترنت الأشياء، ومثيلاتها بشكل خاص. بنتيجة الدراسة تبين أن خوارزمية الغابة العشوائية هي الأفضل والأنسب لإجراء عملية التطوير عليها مستقبلاً. كما قدمنا مقاربة اكتشاف هجينة متطورة ذاتياً وديناميكية، حيث يمكننا التحكم بدقة الكشف التقريبية عبر ضبط برامترات الخوارزميات والبنى الاحتمالية، وعلى الرغم من أن تحقيق مثل هذه المقاربة يعتبر معقداً، لكنها ستحل مشكلات كثيرة تمّ الإشارة إليها سابقاً. في المستقبل سوف نعمل على بناء منهجية جديدة لاكتشاف الشذوذ تشكل تحقيقاً للنموذج المفاهيمي المقترح في هذا العمل بحيث تؤمن اكتشاف البيانات الشاذة في بيئة البيانات الضخمة بشكل عام وبيئة انترنت الأشياء بشكل خاص.
|
| |
Reference
[1]KURNAZ S, Al-Rawi A, "Intrusion Detection System using Apache Spark Analytic System," Journal of Computer Engineering , vol. 21, no. 1, pp. 32-37 , 2019.
[2] Kumar K, Kumar R, "Intrusion Detection System For Big Data Driven Application Using Apache Spark," International Journal of Management, Technology And Engineering, vol. 8, no. XI, pp. 1318-1327, 2018.
[3] Othman S, Ba‑Alwi F, Alsohybe N, Al‑Hashida A, "Intrusion detection model using machine learning algorithm on Big Data environment," Journal Of Big Data, 2018.
[4] Manzoor M, Morgan Y, "Network Intrusion Detection System using Apache Storm," Advances in Science, Technology and Engineering Systems Journal , vol. 2, no. 3, pp. 812-818 , 2017.
[5] Karatas F, Korkmaz S, "Big Data: controlling fraud by using machine learning libraries on Spark," Int J Appl Math Electron Comput. 2018;6(1):1–5.
[6] Mokhtari S, Abbaspour A, Yen K, Sargolzaei A, "A Machine Learning Approach for Anomaly Detection in Industrial Control Systems Based on Measurement Data," MDPI, 2021.
[7]Peng K, Leung V, Huang Q, "Clustering approach based on mini batch Kmeans for intrusion detection system over Big Data," IEEE Access. 2018.
[8] Wang H, Xiao Y, Long Y, "Research of intrusion detection algorithm based on parallel SVM on Spark, " In: 7th IEEE Inter‑ national conference on electronics information and emergency communication (ICEIEC), 2017 . Piscataway: IEEE; 2017. p. 153–156.
[9] Vimalkumar K, Radhika N, "A big data framework for intrusion detection in smart grids using Apache Spark." In: Inter‑ national conference on advances in computing, communications and informatics (ICACCI), 2017. Piscataway: IEEE; 2017. p. 198–204.
[10] Dahiya P, Srivastava D, "Network intrusion detection in big dataset using Spark". Procedia Comput Sci. 2018;132:253–62.
[11] Gurulakshmi K, Nesarani A, "Analysis of IoT Bots against DDOS attack using Machine learning algorithm." International Conference on Trends in Electronics and Informatics (2018).
[12] Belouch M, El Hadaj S, Idhammad M, "Performance evaluation of intrusion detection based on machine learning using Apache Spark." Procedia Comput Sci. 2018;127:1–6.
[13] Saranya T, Sridevi S, Deisy C, Chung T, Khan A, "Performance Analysis of Machine Learning Algorithms in Intrusion Detection System: A Review," Procedia Computer Science, p. 1251–1260, 2020.
[14] Elmrabit N, Zhou F, Li F, Zhou H, "Evaluation of machine learning algorithms for anomaly detection", International Conference on Cyber Security and Protection of Digital Services (Cyber Security). IEEE. 2020.
[15] Shahid M, Blanc G, Zhang Z, Debar H, "Machine Learning for IoT Network Monitoring," 2019.
[16] Chaudhary P, Gupta B, "DDoS Detection Framework in Resource Constrained Internet of Things Domain," IEEE 8th Global Conference on Consumer Electronics (GCCE), 2019.
[17] Hasan M, Islam M, Zarif I, Hashem M, "Attack and anomaly detection in IoT sensors in IoT sites using machine learning approaches," ELSEVIER, 2019.
[18] Dwyer O, Marnerides A, Giotsas V, Mursch T, "Profiling IoT-based botnet traffic using DNS", IEEE Global Communications Conference (GLOBECOM), 2019, pp. 1–6, 2019
[19] Wehbi K, Hong L, Al-salah T, Bhutta A, "A survey on machine learning based detection on DDoS attacks for IoT systems," in: 2019 SoutheastCon, pp. 1–6, 2019.
[20] Stoian N, "Machine Learning for Anomaly Detection in IoT networks: Malware analysis on the IoT-23 Data set," 2021.
[21] Khan Z, Herrmann P, "Recent Advancements in Intrusion Detection Systems for the Internet of Things," Hindawi, 20 May 2019.
[22] Soe Y, Santosa P, Hartanto R, "DDoS attack detection based on simple ANN with SMOTE for IoT environment," in: 2019 Fourth International Conference on Informatics and Computing (ICIC), pp. 1–5, 2019.
[23] Enterprise Big Data Framework, "The Importance of Outlier Detection in Big Data, "[Online]. Available: https://www.bigdataframework.org/the-importance-of-outlier-detection-in-big-data/. [Accessed 5 1 2022].
[24] Marr B, "What Is Metadata – A Simple Explanation of What Everyone Should Know," Bernard Marr & Co. Intelligent Business Performance, [Online]. Available: https://www.bernardmarr.com/default.asp?contentID=1748. [Accessed 24 1 2022].
[25] HARVARD LAW SCHOOL,"What is Metadata?" [Online]. Available: https://hls.harvard.edu/dept/its/what-is-metadata/. [Accessed 7 2 2022].
[26] GAKHOV A, "PROBABILISTIC DATA STRUCTURES AND ALGORITHMS FOR BIG DATA APPLICATIONS," Norderstedt: BoD — Books on Demand GmbH, 2019.
|
| |
up |
|




