|
مواد البحث وطرائقه
في هذه الفقرة نتحدث عن البيانات المستخدمة في عمليات التدريب والاختبار بالإضافة إلى الخوارزميات والتقنيات لإنجاز عمليات التصنيف واستخراج السمات.
1.3. مجموعات البيانات
اعتمدنا في بحثنا على عدة مجموعات للبيانات وذلك نتيجة لتنوع البيانات المستخدمة، تتضمن الأنواع ما يلي:
1.1.3. مجموعة بيانات Spotify 1.2M+ Songs
تحوي (1) قاعدة بيانات Spotify على 1200000 أغنية مع خصائصها الصوتية، تم الحصول عليها من موقع Spotify. يحوي الملف على بيانات مجموعة كبيرة من الأغاني متضمنة خصائصها الصوتية.
2.1.3. مجموعة بيانات كلمات الأغاني
تحوي (2) قاعدة البيانات هذه على مجموعة كبيرة من الأغاني مصنفة إلى المشاعر الأربعة بالاعتماد على الكلمات. حيث تحوي حوالي 1776 أغنية مصنفة حسب الحالة الشعورية للكلمات.
3.1.3. مجموعة بيانات النص مع المشاعر
تحوي (3) قاعدة بيانات الجمل والمشاعر على 48785 جملة مع الحالة الشعورية الموافقة لها.
2.3. تعلم الآلة Machine learning
تعد تقنية تعلم الآلة من تقنيات الذكاء الاصطناعي، وتوجد في العديد من التطبيقات المتطورة من محركات البحث إلى الشبكات الاجتماعية وصولاً إلى أنظمة التوصية للمواقع التجارية.
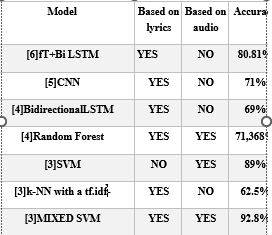
تستخدم أنظمة تعلم الآلة في تحديد الأغراض في الصور وتحويل الكلام إلى نص ومطابقة عناصر جديدة واقتراح عناصر للمستخدم وإظهار النتائج المرغوبة في البحث والعديد من التطبيقات الأخرى [8]. ومن أشهر هذه الخوارزميات Random Forest تستند هذه الخوارزميات إلى أسلوب التعلم غير الخاضع للإشراف وتعتمد على بيانات تدريب حيث تقوم بفرز هذه البيانات لعدة أصناف [9]. وخوارزمية Support Vector Machine (SVM) هي خوارزمية تعلم آلي تتعرف على الأنماط في مجموعات البيانات الكبيرة وتصنف البيانات كفئات [10].
3.3. التعلم العميق Deep learning
التعلم العميق هو تقنية تمكن من حساب النماذج في طبقات معالجة متعددة من أجل معرفة تمثيل البيانات في مراحل متعددة للنتائج. أحدثت شبكات التعلم العميق الالتفافية Deep convolutional nets تقدم كبير في معالجة الصور والفيديو والكلام والصوت، أما الشبكات التكرارية recurrent nets فاستخدمت مع البيانات التسلسلية مثل النص والكلام [8].
1.3.3. الشبكات العصبية التكرارية Recurrent Neural Network (RNN)
الشبكات التكرارية هي شبكات تحوي على حلقات وذاكرة الحالة state memory، وعند بسط الحلقة تصبح شبكة تغذية أمامية تشارك الأوزان. تتشارك شبكات RNNs الأوزان عبر الزمن، وهذا ما يسمح للمعالجة أن تكون فعالة في حالة تمثيل النماذج في البيانات التسلسلية [7].
2.3.3. شبكة الذاكرة الطويلة/القصيرة الأمد Long Short-Term Memory (LSTM) Network
هي نوع خاص من الشبكات العصبية التكرارية التي تملك خلايا ذاكرة تعمل على التقاط الاعتماديات طويلة الأمد في البيانات ليتم تذكر المعلومات عبر الفترات الزمنية الطويلة [11].
3.3.3. خوارزمية Bidirectional LSTM
هي نوع خاص من شبكات RNN تدعى Bidirectional LSTM تستخدم من أجل تحديد الحالة الشعورية للجملة عن طريق التعامل مع كل جملة على أنها سلسلة من الكلمات المترابطة دلاليا. هذا النوع الخاص من الذاكرة الطويلة القصيرة الأمد LSTM يتميز بقدرة على فهم الجملة باتجاهين زمنيين من الماضي إلى الحاضر ومن الحاضر إلى الماضي [11].
4.3. تصنيف مزاج الأغنية بالاعتماد على الخصائص الصوتيةSong mood classification based on Acoustic
استخدمنا قاعدة بيانات Spotify التي تحوي الاغنية مع السمات الصوتية. ولكنها لا تحوي على الحالة الشعورية للأغنية. اعتمدنا طريقة العنقدة Clustering للحصول على الحالة الشعورية بالاعتماد على أربع سمات صوتية وهي (Danceability، Energy، acousticness، Valence)، تم انشاء أربع عناقيد باستخدام خوارزمية KMeans. ويوضح الشكل رقم 1 توزع الحالات الشعورية بالنسبة لسمتي danceability وenergy:
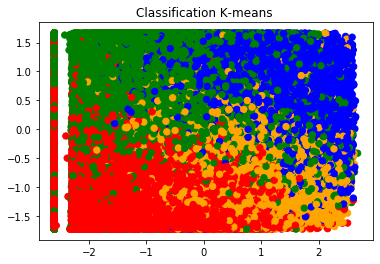
الشكل 1 توزع الحالات الشعورية الأربعة بالاعتماد على سمتي Danceability وEnergy
oاللون الأزرق يدل على الشعور السعيد Happy حيث يكون danceability وenergy ذات قيم مرتفعة.
o اللون الأحمر يدل على الشعور حزين Sad حيث يكون danceability وenergy ذات قيم منخفضة.
o اللون الأخضر يدل على الشعور غاضب Angry حيث يكون energy مرتفع وdanceability منخفض.
o اللون الأصفر يدل على الشعور حيادي Relax حيث يكون danceability وenergy ذات قيم معتدلة.
وبعد علمية العنقدة قمنا بإضافة عمود المزاج Mood إلى قاعدة البيانات وهو معنون labeled بأرقام كل منها يعبر عن حالة شعورية. ثم قمنا ببناء مصنف البيانات الصوتية بالاعتماد على قاعدة البيانات الجديدة التي أنشأتها
تم اختيار بيانات الدخل وهي السمات الأربعة الأكثر أهمية التي استخدمناها في عملية العنقدة، أما الخرج فكان الحالة الشعورية. بعدها دربنا النموذج Model على مجموعة مختلفة من المصنفات وذلك من اجل اختبار أفضل دقة. يوضح الشكل 2 الخطوات المتبعة في استخراج السمات وتحديد المزاج وبعدها عملية تصنيف الأغاني
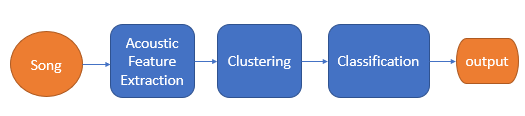
الشكل 2 مخطط مراحل تصنيف الأغاني بالاعتماد على الخصائص الصوتية
5.3. تصنيف مزاج الأغنية بالاعتماد على كلمات الأغنيةSong mood classification based on lyrics
تم تدريب هذا النموذج Model على قاعدة بيانات كلمات الأغنية تحوي على عدد كبير من كلمات الأغاني. تمت عملية معالجة النص وفق المراحل التالية [12]:
o مرحلة التحليل اللغوي للنص او استخراج الرموز Token Extraction في هذه المرحلة تم تحليل النص واختيار المصطلحات المميزة وتسمى هذه العملية Tokenization. ونتج عن هذه العملية مجموعة من الكلمات ذات المعنى الدلالي.
o مرحلة التجزيع Stemming يشير إلى اقتطاع جزء من نهاية الكلمة وإزالة اللواحق المشتقة واعادتها إلى الشكل الأساسي للكلمة كما ورد في القاموس اللغوي.
o نقوم بعدها بإزالة كلمات التوقف واستخدام ترجيح المصطلحات TFIDF. ومعالجة اللغات الطبيعية NLP تتضمن جمع المعارف حول كيفية فهم البشر واستخدامهم للغة. الهدف من معالجة اللغات الطبيعية هو قراءة اللغات البشرية وفهمها وادراكها بطريقة قيمة واستخلاص المعنى المطلوب.
o تم تقسيم العينات إلى بيانات تدريب واختبار وتتألف عملية التدريب من ثلاث مراحل تمت على التوازي Pipeline وهذه المراحل هي: عملية ترجيح المصطلحات واستخراج السمات باستخدام التابع TfidfVectorizer، واختيار أفضل السمات.
o دربنا النموذج Model على مجموعة مختلفة من المصنفات وذلك من اجل اختبار أفضل دقة. ومن ثم قمنا بتصنيف النص إلى أربع مشاعر الأساسية الأربعة وهي (سعيد، حزين، حيادي، غاضب).
يوضح الشكل رقم 3 مراحل تصنيف الأغاني بالاعتماد على كلمات الأغنية بداية من استخراج الكلمات ومعالجة النص وصولاً إلى التصنيف وإعطاء الخرج
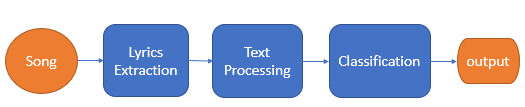
الشكل 3 مخطط مراحل تصنيف الأغاني بالاعتماد على كلمات الأغنية
6.3. موديل تصنيف مزاج الأغنية بالاعتماد على الجملSong mood classification based on Sentence
استخدمنا قاعدتي بيانات الجمل وكلمات الأغاني لتدريب النموذج Model، ومن أجل عمليات معالجة النصوص استخدمنا خوارزميات معالجة اللغات الطبيعية NLP، وبعدها حضرنا الكلمات لندخلها إلى شبكة RNN. المرحلة التالية كانت بتقسيم الأغنية إلى جمل وتحديد عدد الكلمات المطلوب في كل جملة. قمنا بتحديد التسلسل الزمني للكلمات لأخذ الكلمات بالشكل الصحيح. يوضح الشكل رقم 4 مراحل تصنيف الأغاني بالاعتماد على الجملة الكاملة للأغنية بداية من استخراج الكلمات ومعالجة النص وتطبيق قيود دلالية وصولاً إلى التصنيف وإعطاء الخرج النهائي

الشكل 4 مخطط مراحل تصنيف الأغاني بالاعتماد على الجملة الكاملة للأغنية
نظرا لأن كمية الجمل الحيادية relax في الكلام المحكي أكثر من الجمل الحاوية على مشاعر سلبية أو إيجابية فإن المصنف LSTM سينحاز نوعا ما للصنف RELAX ولحل هذه المشكلة تم الاعتماد على Sentiment Analyzer خاص بمكتبة NLTK يعطي 4 بارامترات تتعلق بإيجابية وسلبية وحيادية وقطبية كل جملة وبالنسبة للبارامترات الثلاث الأولى فهي تتراوح بين المجال [0-1]. فإذا أعطى مصنف LSTM تصنيف Relax يتم تطبيق القيود المذكورة للتأكد أن الجملة فعلا Relax أو يتم تغيير تصنيفها ليصبح Sad أو Happy حسب قيم البارامترات. من جهة ثانية تم وضع قيود كذلك على الصنف Happy نظرا لوجود نوع من الانحياز تجاه الجمل السعيدة بحيث يتم التأكد أنها بالفعل جمل سعيدة إذا حققت القيود المذكورة. فإذا أعطى مصنف LSTM تصنيف Happy يتم التأكد من بارامترات الحيادية والسلبية والإيجابية والقطبية فإن لم تكن القطبية موجبة وقيم الإيجابية فوق عتبة معينة سيتم إعادة النظر بهذه الجمل وتغيير تصنيفها لتصبح Relax أو Sad. تم وضع بعض القيود على خوارزمية BidirectionalLstm المستخدمة في تحديد الحالة الشعورية لكل جملة وذلك لتحسين دقة التصنيف وقد قمنا بذلك عن طريق أخذ 4 متغيرات بعين الاعتبار وهي:
Positive: مقدار إيجابية الجملة. Negative مقدار سلبية الجملة. Neutral: مقدار حيادية الجملة. Compound: القطبية والتي تؤخذ قيم سالبة في الجمل الحزينة والغاضبة. تم استخراج المتغيرات السابقة عن طريق خوارزمية تحليل المشاعر Sentiment Analyzer. وهذه القيود موضحة في الجدول رقم 1:
الجدول 1القيود الموضوعة على المصنف بالاعتماد على الجمل

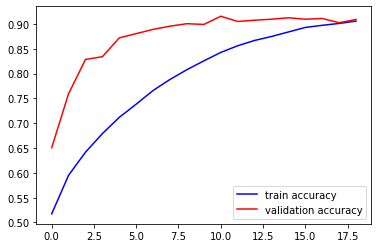
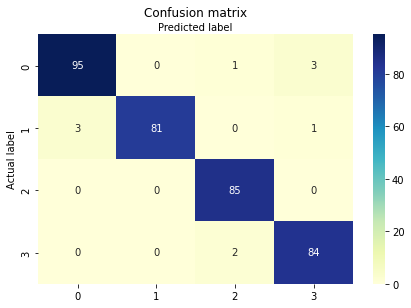
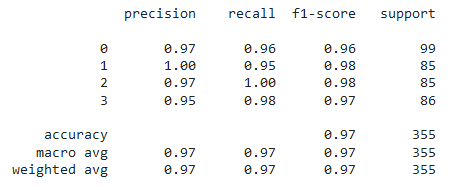
إن استخدام القيود السابقة ساعد على رفع دقة الخوارزمية بمقدار 0.3% حيث أصبحت الدقة 90%. وأخيراً قمنا بإنشاء نموذج التعلم العميق وهو عبارة عن شبكة عصبية تكرارية RNN حيث استخدمنا شبكة Bidirectional LSTM والشكل رقم 5 يوضح بينة هذا النموذج:
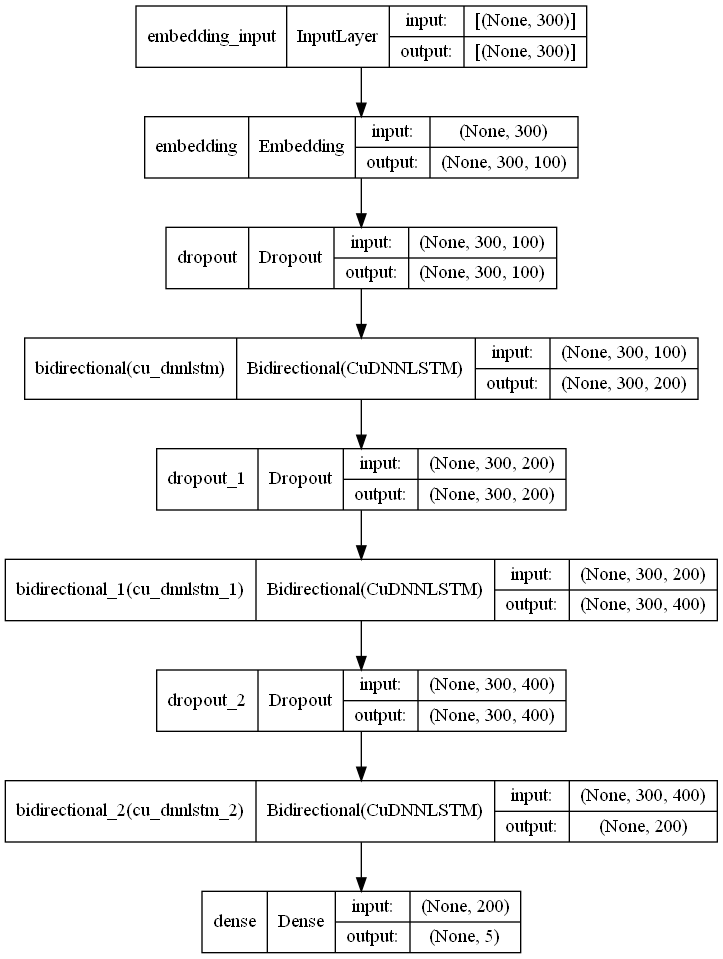
الشكل 5 موديل Bidirectional LSTM
تبدأ البينة العصبية الكاملة للخوارزمية بطبقة التضمين Embedding تعقبها 3 طبقات من Bidirectional LSTM مع استخدام Drop Out بينية لتفادي حالة Overfitting وبعد ذلك تأتي طبقة الخرج ب 5 عصبونات للإشارة للأصناف الخمسة التي تم تدريب الخوارزمية عليها وهي: Angry, Sad, Relax, Love, Happy لاحقا سيتم اعتبار كل من Love وHappy كحالة واحدة. تم استخدام تابع تنشيط SoftMax على الخرج وتحديد Categorical Cross Entropy لحساب الخسارة Loss بالإضافة لاستخدام تقنية Early Stopping لإيقاف الخوارزمية عن التدريب عند عدم وجود أي تحسن إضافي بالإداء. اعتمدت الخوارزمية على 25 دورة تدريبية وبسبب وجود تقنية Early Stopping تم التوقف عند الدورة 19. بالنسبة للجمل فقد تمت معالجتها وفق Text Hammer وتم أخذ جميع الجمل بعدد كلمات ثابت وهو شعاع مكون من 300 قيمة وفي حال كانت الجمل أقل من ذلك تم حشو أصفار لتجسيد عدم وجود كلمات كافية وتحقيق البعد المطلوب.
المنهجية المقترحة
في هذا البحث تم اقتراح نهج جديد لتصنيف الأغاني يعتمد على دمج عدة مصنفات مع بعضها ضمن نموذج شامل Fusion Model ويوضح الشكل رقم 6 المخطط العام للمنهجية المقترحة حيث تم استخلاص عدة مدخلات من كل أغنية وهي:
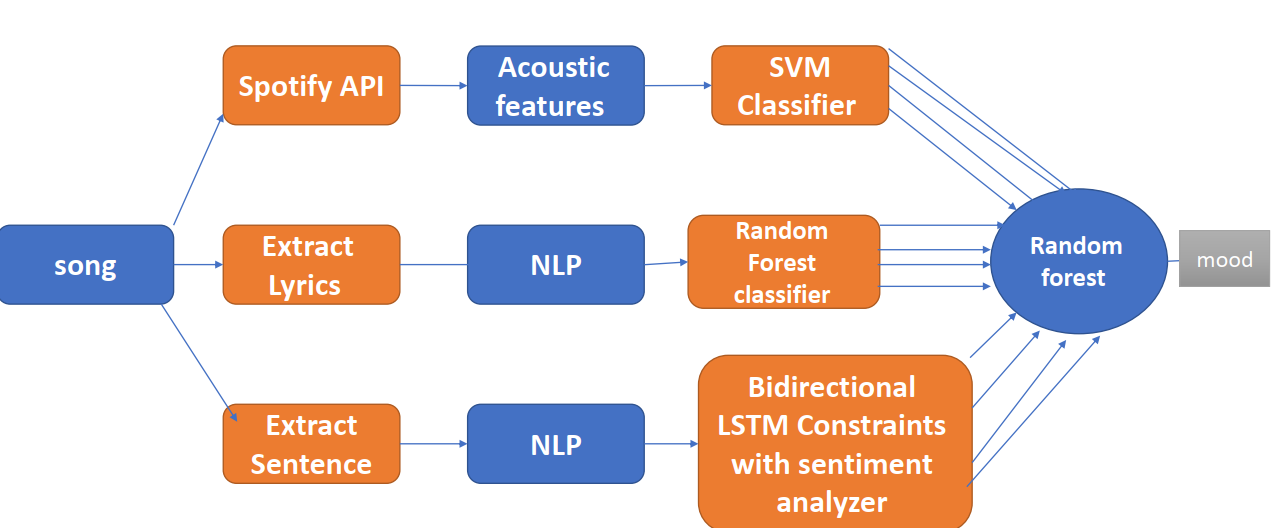
الشكل 6 المخطط العام للمنهجية المقترحة
كلمات الأغنية Lyrics: خضعت الكلمات لمعالجة تحضيرية وتم استخدام خوارزمية Random Forest. الخصائص الصوتية Acoustic: تم استخلاص مجموعة من الخصائص الصوتية ومن ثم تم استخدام خوارزمية SVM. الجمل Sentence: تم استخلاص الجمل المكونة للأغنية، وقد خضعت هذه الجمل لمعالجة تحضيرية ومن ثم تم استخدام خوارزمية LSTM مع مجموعة قيود. مصنف الدمج Fusion Model: استقبل هذا المصنف دخله من مخرجات المصنفات السابقة لتحديد التصنيف النهائي حيث أرسل كل مصنف أربعة قيم تمثل احتمالية لمزاج الأغنية (happy sad, angry, relax,) من وجهة نظر المصنف وقام مصنف الدمج بتحليل جميع المدخلات باستخدام خوارزمية Random Forest ومن ثم قام بتحديد التصنيف النهائي.
up
|