| |
Abstract
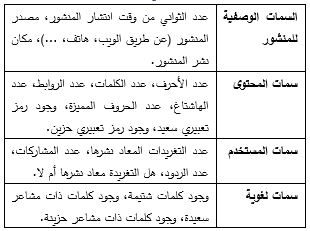
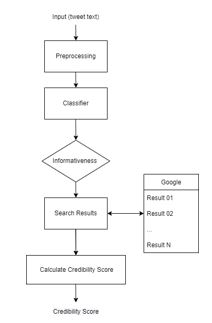
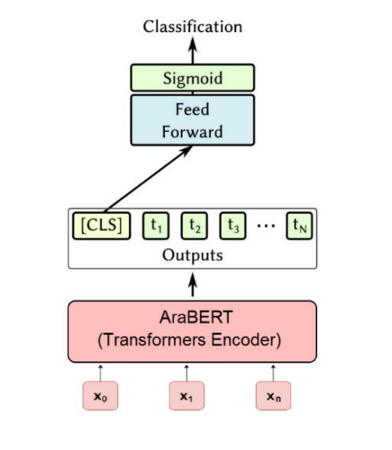
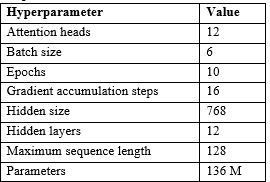
Recently, online social networks, like Twitter, Facebook, Instagram, and others have revolutionized interpersonal communication and allowed millions of users of different ages and genders to develop their social and professional relationships, which increased spreading false information and fake news. Fake news is especially prevalent in the events and pandemics like the covid-19 pandemic, leading to individuals accepting bogus and potentially deleterious claims and articles. Quick detection of fake news can reduce the spread of panic and confusion among the public. In this article, we present our approach to analyze the credibility of Arabic information on social media, which is presented in the form of a two-step pipeline. The first step classifies the tweet if it contains information or not, and the second step calculates the distance between the tweet text and the titles obtained from the search results to calculate the credibility of the tweet.
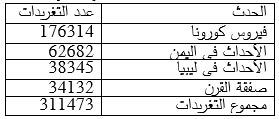
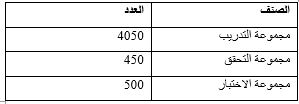
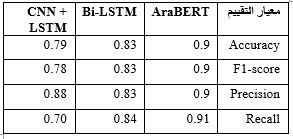
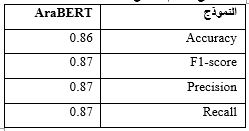
We built an Arabic annotated data set of 5,000 tweets. The proposed approach was evaluated on built dataset and on NLP4IF 2021 dataset. The results showed that the results on the built dataset were better and it equals 0.91
up
|
| |
Reference
[1] Castillo, Carlos & Mendoza, Marcelo & Poblete, Barbara. (2013). Predicting information credibility in time-sensitive social media. Internet Research: Electronic Networking Applications and Policy. 23. 10.1108/IntR-05-2012-0095.
[2]Antoniadis, Sotiris & Litou, Iouliana & Kalogeraki, Vana. (2015). A Model for Identifying Misinformation in Online Social Networks. 473-482. 10.1007/978-3-319-26148-5_32.
[3]Tacchini, Eugenio & Ballarin, Gabriele & Della Vedova, Marco & Moret, Stefano & Alfaro, Luca. (2017). Some Like it Hoax: Automated Fake News Detection in Social Networks.
[4]Shao, Chengcheng & Ciampaglia, Giovanni & Varol, Onur & Flammini, Alessandro & Menczer, Filippo. (2017). The spread of fake news by social bots.
[5]Vosoughi, Soroush & Roy, Deb & Aral, Sinan. (2018). The spread of true and false news online. Science. 359. 1146-1151. 10.1126/science.aap9559.
[6]Vargo, Stephen & Akaka, Melissa & Vaughan, Claudia. (2017). Conceptualizing Value: A Service-ecosystem View. Journal of Creating Value. 3. 239496431773286. 10.1177/2394964317732861.
[7] Shaar, Shaden & Alam, Firoj & Da San Martino, Giovanni & Nikolov, Alex & Zaghouani, Wajdi & Nakov, Preslav & Feldman, Anna. (2021). Findings of the {NLP4IF}- 2021 Shared Task on Fighting the {COVID}- 19 Infodemic and Censorship Detection. In Proceedings of the Fourth Workshop on Natural Language Processing for Internet Freedom: Censorship, Disinformation, and Propaganda.
[8]https://books.google.ae/books/about/New_New_Media.html?id=G009uwAACAAJ& redir_esc=y
[9] Singh, Lisa & Bansal, Shweta & , Bode & Leticia, Ceren & Chi, Guangqing & Kawintiranon, Kornraphop & Padden, Colton & Vanarsdall, Rebecca & Vraga, Emily & Wang, Yanchen.( 2020). A first look at COVID-19 information and misinformation sharing on Twitter. arXiv 2020, arXiv:2003.13907 .
[10]Thota, A.; Tilak, P.; Ahluwalia, S.; Lohia, N. Fake News Detection: A Deep Learning Approach. SMU Data Sci. Rev. 2018, 1, 10.
[11] Cui, Limeng & Lee, Dongwon.(2020). CoAID: COVID-19 Healthcare Misinformation Dataset. arXiv 2020, arXiv:2006.00885.
[12] Qarqaz, Ahmed & Abujaber, Dia & A. Abdullah, Malak. (2021). R00 at NLP4IF-2021: Fighting COVID19 infodemic with transformers and more transformers. In Proceedings of the Fourth Workshop on Natural Language Processing for Internet Freedom: Censorship, Disinformation, and Propaganda, NLP4IF@NAACL’ 21.
[13] Hussein, Ahmad & Ghneim, Nada & Joukhadar, Ammar. (2021). DamascusTeam at NLP4IF2021: Fighting the Arabic COVID-19 Infodemic on Twitter Using AraBERT. In Proceedings of the Fourth Workshop on NLP for Internet Freedom: Censorship, Disinformation, and Propaganda. pages 93-98.
up
|