| |
المراجع
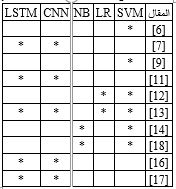
[1] G. Badaro, R. Baly, H. M. Hajj, W. El-Hajj, K. B. Shaban, N. Habash, A. Al-Sallab and A. Hamdi, "A survey of opinion mining in Arabic: A comprehensive system perspective covering challenges and advances in tools, resources, models, applications, and visualizations," 2019.
[2] A.-M. Founta, D. Chatzakou, N. Kourtellis, J. Blackburn, A. Vakali and I. Leontiadis, "A unified deep learning architecture for abuse detection," in WebSci 2019 – Proceedings of the 11th ACM Conference on Web Science, 2019.
[3] C. Themeli, G. Giannakopoulos and N. Pittaras, "A study of text representations for Hate Speech Detection," in In Proceedings of the 20th International Conference on Computational Linguistics and Intelligent Text Processing,, La Rochelle, France, 2019.
[4] M. Alrefai, H. Faris and I. Aljarah, "Sentiment analysis for Arabic language: A brief survey of approaches and techniques," International Journal of Advanced Science and Technology, vol. 119(1), pp. 13-24, 2018.
[5] W. Warner and J. Hirschberg, "Detecting hate speech on the World Wide Web," in the Second Workshop on Language in Social Media 2012 Jun 7, 2012.
[6] A. Omar, T. M. Mahmoud and T. A. El-hafez, "Comparative Performance of Machine Learning and Deep Learning Algorithms for Arabic Hate Speech Detection in OSNs," 2020.
[7] I. Abu-Farha and W. Magdy, "Multitask Learning for Arabic Offensive Language and Hate-Speech Detection," in Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, 2020.
[8] H. Mubarak and K. Darwish, "Arabic offensive language classification on twitter," in International Conference on Social Informatics, 2019.
[9] A. Alakrot, L. Murray and N. S. Nikolov, "Towards accurate detection of offensive language in online communication in Arabic," in Procedia computer science, 2018.
[10] N. Albadi, M. Kurdi and S. Mishra, "Are they our brothers? analysis and detection of religious hate speech in the Arabic twitter sphere," in n 2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), 2018.
[11] H. Faris, I. Aljarah, M. Habib and P. A. Castillo, "Hate Speech Detection using Word Embedding and Deep Learning in the Arabic Language Context," in Proceedings of the 9th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2020), 2020.
[12] A. Abuzayed and T. Elsayed, "Quick and Simple Approach for Detecting Hate Speech in Arabic Tweets," in The 4thWorkshop on Open-Source Arabic Corpora and Processing Tools with a Shared Task on Offensive Language Detection, 2020.
[13] B. Haddad, Z. Orabe, A. Al-Abood and N. Ghneim, "Arabic Offensive Language Detection with Attention-based Deep Neural Networks," in Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, 2020.
[14] H. Mulki, H. Haddad, C. B. Ali and H. Alshabani, "L-HSAB: A Levantine Twitter Dataset for Hate Speech and Abusive Language," in Proceedings of the Third Workshop on Abusive Language Online, Florence, Italy, 2019.
[15] S. Stieglitz, M. Mirbabaie, B. Ross and C. Neuberger, "Social media analytics – challenges in topic discovery, data collection, and data preparation," International Journal of Information Management, vol. 39, pp. 156-168, 2018.
[16] A. G. Chowdhury, A. Didolkar, R. Sawhney and R. R. Shah, "ARHNet – leveraging community interaction for detection of religious hate speech in Arabic," in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: Student Research Workshop, Florence, Italy, 2019.
[17] H. Mohaouchane, a. Mourhir and N. S. Nikolov, "Detecting offensive language on Arabic social media using deep learning," in 2019 Sixth International Conference on Social Networks Analysis, Management and Security, 2019.
[18] H. Haddad, H. Mulki and A. Oueslati, "T-HSAB: A Tunisian hate speech and abusive dataset," Springer International Publishing, 2019.
[19] H. Mubarak, K. Darwish and W. Magdy, "Abusive language detection on Arabic social media," in Proceedings of the First Workshop on Abusive Language Online, Stroudsburg, 2017.
[20] J. Ramos, "Using tf-idf to determine word relevance in document queries," in Proceedings of the first instructional conference on machine learning, 2003.
[21] T. Mikolov, K. Chen, G. Corrado and J. Dean, "Efficient Estimation of Word Representations in Vector Space," in In the Proceedings of Workshop at ICLR, 2013.
[22] A. B. S. Mohammad, K. Eissa and S. R. El-Beltagy, "AraVec: A set of Arabic Word Embedding Models for use in Arabic NLP," in the 3rd International Conference on Arabic Computational Linguistics (ACLing 2017), Dubai, UAE, 2017.
[23] T. Mikolov, I. Sutskever, K. Chen, G. Corrado and J. Dean, "Distributed representations of words and phrases and their compositionality," in Advances in neural information processing systems, 2013.
[24] S. Russell and P. Norvig, Artificial Intelligence: A modern approach, Pearson Education, lnc., 1995.
[25] D. D. Lewis, "Naive (bayes) at forty: The independence assumption in information retrieval," in European conference on machine learning, 1998.
[26] S. W. Menard, Applied logistic regression analysis, ThousandOaks,: Sage university paper series on quantitative application in the social sciences, series no. 106) (2nd ed.), 1995.
[27] I. Goodfellow, Y. Bengio and A. Courville, Deep Learning, Cambridge, MA, USA: MIT Press, 2016.
[28] S. Shaikh and S. M. Doudpotta, "Aspects Based Opinion Mining for Teacher and Course Evaluation," Sukkur IBA Journal of Computing and Mathematical Sciences, vol. 3(1), pp. 34-43, 2019.
[29] S. Qiu, B. Xu, J. Zhang, Y. Wang, X. Shen, G. Melo, C. Long and X. Li, "EasyAug: An Automatic Textual Data Augmentation Platform for Classification Tasks," in Companion Proceedings of the Web Conference 2020, 2020.
[30] M. V. Chawla, K. W. Bowyer, L. O. Hall and W. P. Kegelmeyer, "SMOTE: synthetic minority over-sampling technique," Journal of Artificial Intelligence Research, vol. 16, no. 1, pp. 321-357, 2002.
[31] A. Liaw and M. Wiener, "Classification and regression by randomforest," Forest, vol. 23, 2002.
[32] M. Ashi, M. A. Siddiqui and F. Nadeem, "Pre-trained Word Embeddings for Arabic Aspect-Based Sentiment Analysis of Airline Tweets," Proceedings of the International Conference on Advanced Intelligent Systems and Informatics Proceedings of the International Conference on Advanced Intelligent Systems and Informatics 2018, 2019.
[33] H. Mubarak, K. Darwish, W. Magdy, T. Elsayed and H. Al-Khalifa4, "Overview of OSACT4 Arabic Offensive Language Detection Shared Task," in Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, 2020.
[34] M. Zampieri, P. Nakov, S. Rosenthal, P. Atanasova, G. Karadzhov, H. Mubarak, L. Derczynski, Z. Pitenis and Ç. Çöltekin, "SemEval-2020 Task 12: Multilingual Offensive Language Identification in Social Media (OffensEval 2020)," in In Proceedings of the Fourteenth Workshop on Semantic Evaluation, Barcelona (online), 2020.
[35] A. Safaya, M. Abdullatif and D. Yuret, "KUISAIL at SemEval-2020 Task 12: BERT-CNN for Offensive Speech Identification in Social Med," in In Proceedings of the Fourteenth Workshop on Semantic Evaluation, 2020.
up
|