|
منهجية العمل
يظهر (الشكل 1) منهجية العمل التي تقوم على طرح سؤال باللغة العربية (لا توجد له إجابة في مصادر اللغة المتوفرة) وترجمته للإنكليزية باستخدام إحدى بنيتي الترجمة الآلية وذلك للبحث ضمن نسخة ويكبيديا الإنكليزية لعام 2019 عن الإجابة وإعادة المقطع الذي يحتوي الإجابة بالإنكليزية ودراسة تأثير الترجمة على جودة الإجابة المستردة.
ويتم بناء كل من نظامي الترجمة الآلية باستخدام مجموعات بيانات متوازية مختلفة و نموذج مسبق التدريب للاستفادة من الأوزان السابقة وتطويرها، حيث يتم توليد نموذجين جديدين للترجمة الآلية.
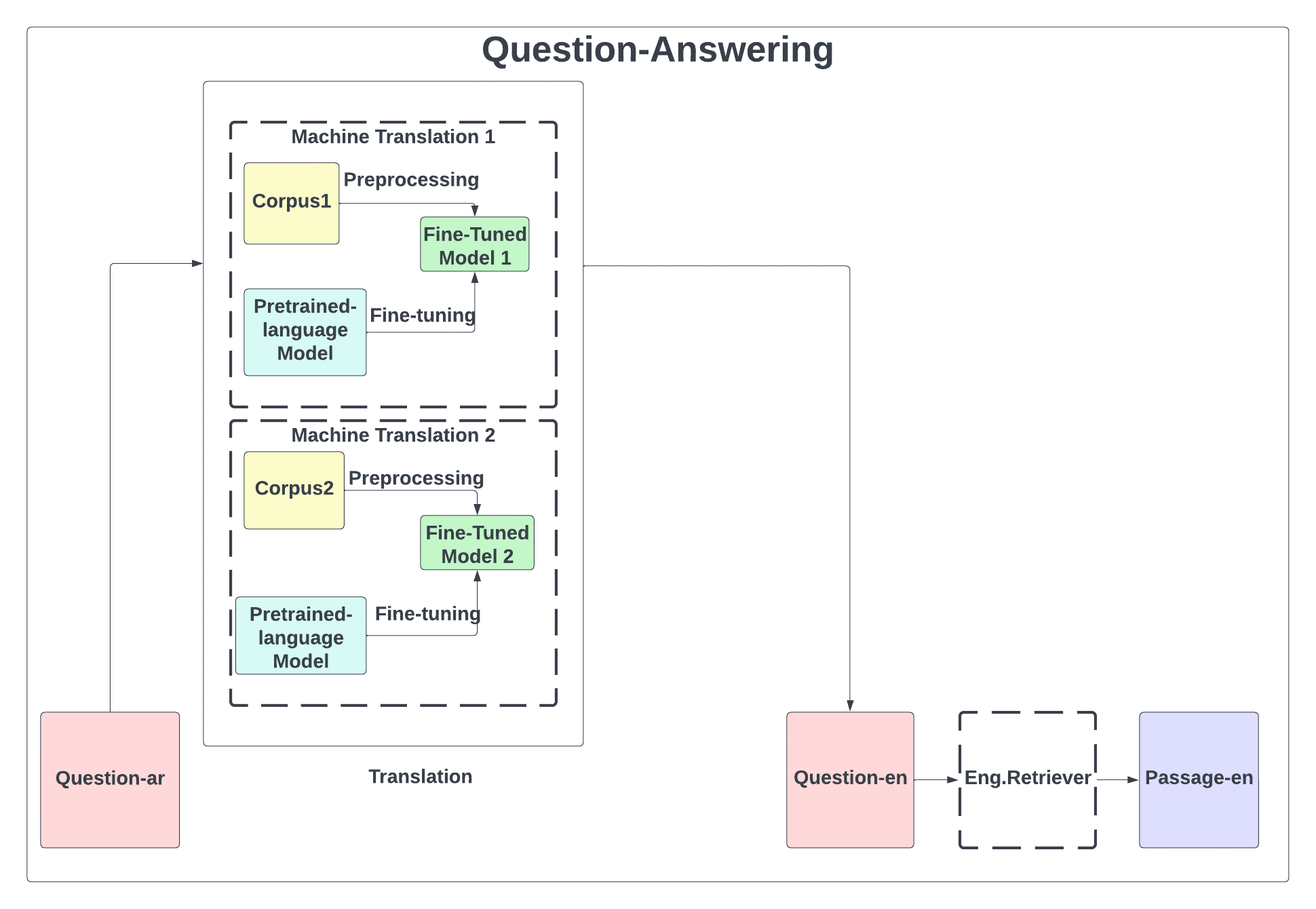
الشكل 1 المخطط العام للمنهجية المقترحة
يتضمن بناء نموذج الترجمة الآلية مراحل المعالجة المسبقة لبنية البيانات لتكون ملائمة للحالة المدروسة وصقل النموذج مسبق التدريب حيث تستخدم الأوزان السابقة للشبكة العصبونية العميقة في تطوير نموذج جديد بما يتوافق مع الهدف المدروس بحيث يكون النموذج الناتج هو نموذج مطوّر مصمم لحل المسألة المدروسة.
3.1 النموذج مسبق التدريب
النموذج المختار هو نموذج (Helsinki-NLP/opus-mt-ar-en) وهو نموذج لغوي للترجمة من العربية للإنكليزية مطوّر من قبل جامعة هلسينكي على مجموعة بيانات متوازية عربية-انكليزية معروفة ب OPUS “” وهي أكبر مجموعة بيانات متوازية مفتوحة المصدر على الإنترنت لأغراض غير ربحية.
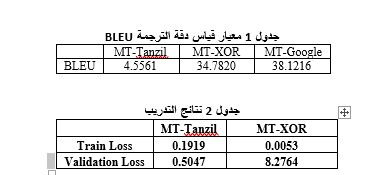
وتم اختيار هذا النموذج لأنّه يعتمد بنية المحوّل [2] لأنّها من بين أحدث البنى الفعّالة في الترجمة الآلية والتي تناسب الجمل الطويلة ولأنه نموذج مفتوح المصدر حيث يمكن إعادة توليده وتطويره وهو مصمم بغرض الترجمة مما يسهل عملية الصقل وحقق النموذج عبر معيار البلو (BLEU): 49.9 عن مجموعة بيانات اختبار تدعى “tatoeba.ar.en” ضمن مسابقة عالمية لتوليد أفضل نماذج الترجمة وهو بذلك يحقق دقة أعلى نماذج الترجمة للعربية المتوفرة ضمن المسابقة.
3.2 مجموعة بيانات التدريب المتوازية
3.2.1 مجموعة البيانات الأولى: مجموعة بيانات تنزيل "Tanzil"
وهي مجموعة بيانات تمثّل ترجمة القرآن وتفاسيره ب 42 لغة.
تم اختيار هذه المجموعة من البيانات لأنّها بيانات تم التحقق منها بدرجة عالية من قبل مشروع تنزيل وبسبب وجود علامات التشكيل التي تصنع فارقاً في اللغة العربية وأيضاً احتوائها على القيود الفنية لرسم الحروف العربية وتحتوي عدد كبير من أزواج اللغات مما يساعد في توسعة البحث مستقبلاً.
حيث تحتوي حجم بيانات كبير يصل إلى 187052 جملة متوازية بين العربية والإنكليزية.
3.2.2 مجموعة البيانات الثانية: مجموعة بيانات الأسئلة [1] " XOR-TyDi" :
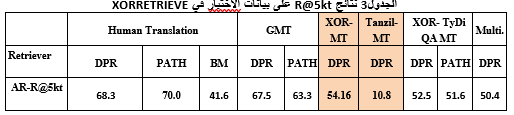
أول مجموعة بيانات تضم للمرة الأولى أسئلة مفتوحة وباحثة عن المعلومات (Information-Seeking)، وهي مجموعة بيانات مطوّرة عن [6] مجموعة بياناتTyDiQA حيث كانت الأسئلة المطروحة هي أسئلة حقيقية مولّدة من قبل أشخاص يبحثون عن الإجابات وليست كمجموعات البيانات التقليدية السابقة [7] XQuAD، مثلاً في XQuAD الأسئلة مولّدة بشكل صنعي حيث يوجد نصوص ويتم استخراج الأسئلة من هذه النصوص. وبذلك تكون الأسئلة أسئلة حقيقية تمثل الاهتمامات الفعلية للأشخاص. وهي مجموعة مؤلفة من ترجمة 30 ألف سؤال باحث عن المعلومات عبر سبع لغات مختلفة في البنية. وطرحت الأسئلة من قبل متحدثين لا تكون لغتهم الأصلية هي الإنكليزية وبذلك يتم تمثيل تطبيقات العالم الحقيقي. وأطلقت هذه المجموعة للتدريب فقط. حيث تتكون من زوج لغوي بين الإنكليزية وباقي اللغات مثل العربية أو اليابانية. وتضم حوالي 4646 زوج من الأسئلة بين العربية والإنكليزية طرحها مستخدمون حقيقيون.
4 الدراسة التجريبية:
4.1 تطوير النموذج
اعتمد تطوير النموذج على مبدأ الصقل (fine-tune) لأنّ إعادة توليد النموذج من الصفر هي إعادة اختراع العجلة حيث نختار النموذج الذي حقق أعلى النتائج ونحاول تطويره اعتماداً على بنية سابقة عن طريق استخدام الأوزان المحفوظة في أفضل نتيجة سابقة والانطلاق منها لتدريب نموذج جديد. علاوةً على أنّ توليد نموذج من الصفر يحتاج إلى موارد ضخمة خاصة في مجال معالجة اللغات الطبيعية ويحتاج إلى عدة وحدات معالجة GPU.
لذلك فقد تم اختيار نموذج للترجمة عام الأغراض مدرّب وفق شبكة عصبونية عميقة هي [2] ولم يتم اعتماد الطرق الإحصائية التقليدية وتم صقله واستخدام تابع أمثلة جديد هو AdamWeightDecay ليلائم مسألة الإجابة على الأسئلة وعبر مجموعة بيانات مناسبة لتوليد نظام مفتوح المصدر قريب من نظام شركة غوغل بموارد محدودة.
4.2 إعدادات النموذج
تم اعتماد نموذج من جامعة هيلسنكي (Helsinki-NLP/opus-mt-ar-en) وفق المعاملات التالية اللغة المصدر: العربية ومجموعة البيانات: OPUS والنموذج: transformer-align والمعالجة المسبقة للبيانات تضمّنت مكتبات معالجة الجمل: normalization + SentencePiece.
4.3 المعالجة المسبقة للبيانات:
من أجل مجموعتي البيانات اعتمدنا التقسيم وفق المنهجية 90 % للتدريب و10% للباقي تُقسم إلى نصفين نصف للاختبار ونصف للتحقق.
اعتمد البحث على التوجّه العلمي بالإبقاء على كلمات التوقف (stop words) وعلامات الترقيم كونها قد تحمل دلالات مهمة في الأسئلة. ومن أهم النقاط التي يجب ذكرها أنّه عند تدريب النموذج الجديد يجب استخدام نفس الترميز (tokenizer) للنموذج السابق للحفاظ على التناسق. وتم تحديد الحجم الأعظمي للدخل والخرج بحيث لا يتخطى 128 وفي حال تجاوز الحد، وضعنا الحل في اقتطاع أو حذف الكلمات الزائدة في الجملة.
فكان حجم مجموعة البيانات الأولى: 18705 جملة متوازية بين اللغة العربية والإنكليزية قسّمت بالترتيب إلى "168346" للتدريب وأيضًا "9353” للاختبار ومثلها للتحقق.
أمّا حجم مجموعة البيانات الثانية: 4646 زوج من الأسئلة بين العربية والإنكليزية قُسّمت على الترتيب إلى "4185" سؤال متوازي للتدريب و"232" للاختبار و"232" للتحقق.
4.4 معاملات (بارامترات) التدريب
تم تحديد حجم التجميعة (Batch size) ب 16 ونسبة التعلّم ب 2e-5 وweight_decay=0.01، واختيار تابع الأمثلة المناسب وهو [8]AdamWeightDecay حيث أنّه تطوير عن [9]ADAM.
تم التدريب على وحدة معالجة صورية (NVIDIA GeForce RTX 2070 Super) وتم اعتماد مبدأ حفظ الأوزان ومن ثم إعادة التدريب من نقطة توقف معينة لملائمة حجم البيانات الكبير مع قدرات الحاسب.
|